細節
軟體架構的目標是什麼?
在 Clean Architecture 一書中,Uncle Bob 指出可維護性是優秀架構的關鍵目標,我們希望最大限度地減少構建和維護系統的開發工作: 軟體架構的目標是最大限度地減少構建和維護所需系統所需的人力資源。來源參考
讓我們回顧一下資料庫的觀點
Clean Architecture 生成獨立於資料庫的系統。更具體地說,業務規則未綁定到資料庫。
- 可測試性:我們可以對業務規則進行單元測試,因為業務規則是在用例和實體中實現的,而不是在資料庫中實現的
- 可維護性:我們可以降低維護成本,因為業務規則既是可測試的,而且我們的應用程式是模組化的(將用例與 I/O 問題分離)
- 可移植性:我們可以將一個資料庫換成另一個資料庫,例如,從 MySQL 切換到 SQL Server 再到 MongoDB 等。
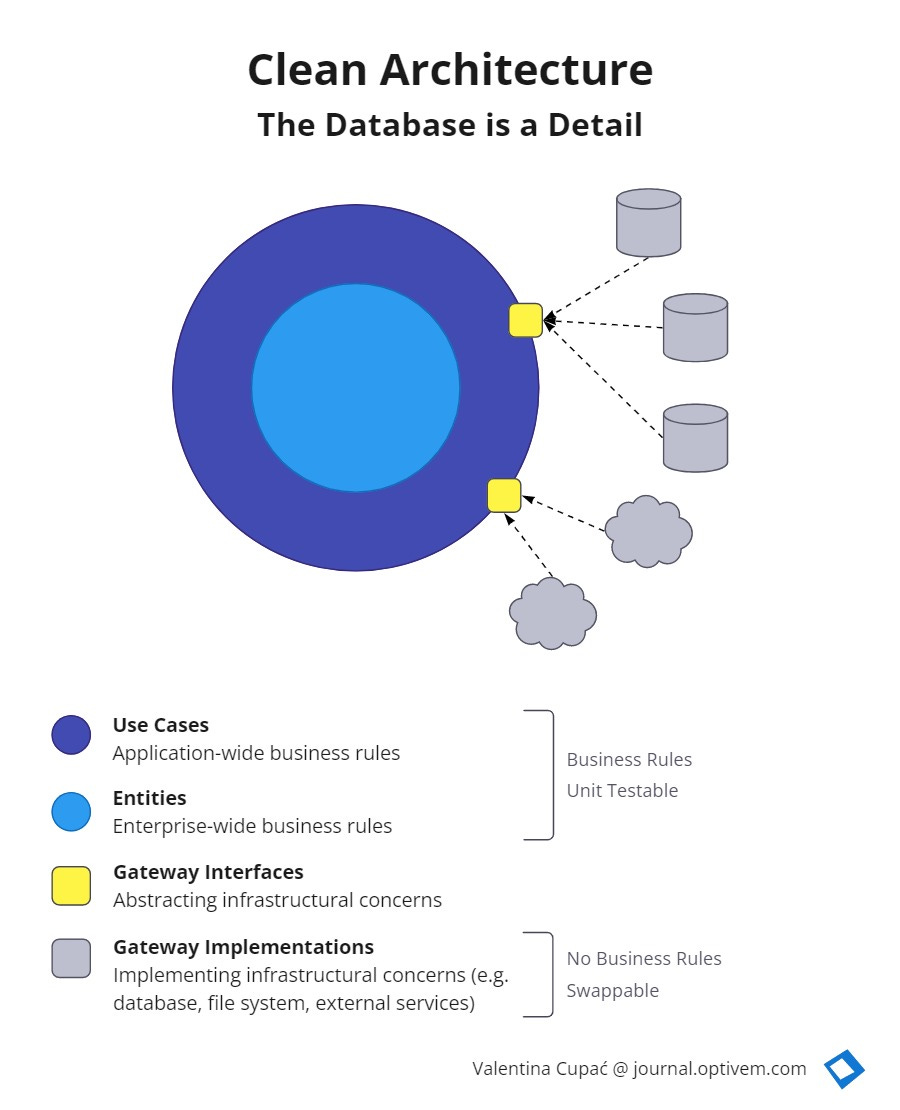
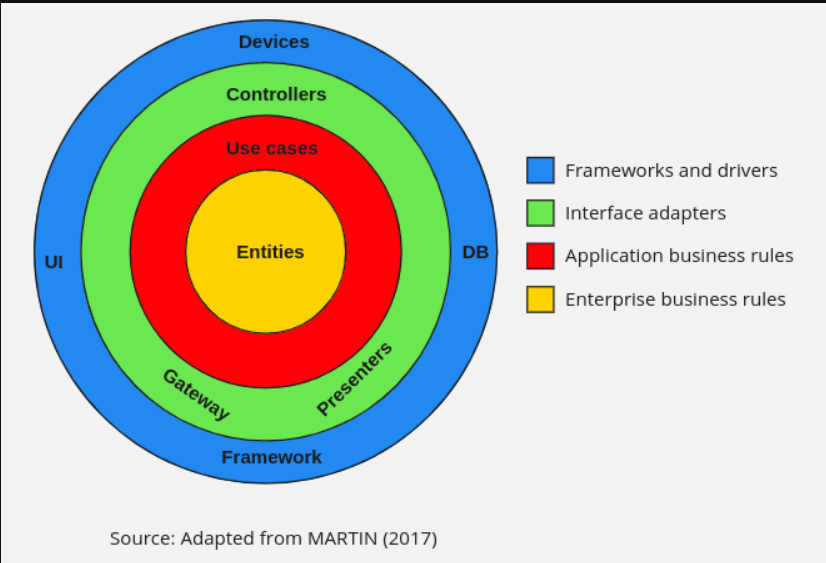
Clean Architecture 的概念由 Robert C. Martin (MARTIN, 2017) 在他的書中定義,題為“Clean Architecture: A Craftsman's Guide to Software Structure and Design”。在此體系結構中,系統可以分為兩個主要元素:策略和詳細資訊。策略是業務規則和過程,詳細資訊是執行策略所需的專案。(馬丁,2017 年)正是從這個劃分開始,Clean Architecture 開始將自己與其他架構模式區分開來。架構師必須創建一種方法,使系統能夠將策略識別為系統的主要元素,而將細節識別為與策略無關。來源參考
在乾淨的架構中,
沒有必要在開發開始時選擇資料庫或框架,因為所有這些都是不會干擾策略的細節,因此可以隨著時間的推移而改變。
在 Clean Architecture 中,有一個明確定義的層劃分。該架構是獨立於框架的,即包含業務規則的內部層不依賴於任何第三方庫,這允許開發人員將框架用作工具,而不是調整系統以滿足特定技術的規範。Clean Architecture 的其他好處是:可測試性、UI 獨立性、資料庫獨立性和獨立於任何外部代理(業務規則不應瞭解外部世界的介面)。
為了說明所有這些概念,創建了下圖所示的圖表。
圖中的每一層都表示軟體的不同區域,最內層是策略,最外層是機制。關係圖的最外層通常由框架和資料庫組成。此層包含與 interface adapters 層建立通信的代碼。所有細節都在這一層,Web 是一個細節,資料庫是一個細節。所有這些元素都位於最外層,以避免干擾其他元素的風險(MARTIN,2017 年)。
本章重點
- 資料庫只是實現細節
- 資料庫不應該影響系統架構,它只是存取資料的工具。
- 資料庫在軟體架構中只是個工具,並不應該影響系統的核心架構。
- 資料庫只是硬碟與記憶體之間傳輸數據的手段,對系統架構無關緊要。
- 關聯式資料庫的歷史
- 關聯式資料庫自1970年代以來成為主要的資料儲存形式。
- 關聯模型雖然優秀,但仍然只是技術細節,應用程式不應該依賴其結構。
- 硬碟的影響
- 硬碟的發展推動了資料庫系統的普及,但硬碟的訪問速度限制了其性能。
- 一段軼事
- 作者分享了在創業公司中堅持不使用關聯型資料庫的經歷,最終認識到市場需求的重要性。
- 未來展望
- 假設磁碟不存在會怎樣:如果所有數據都存在記憶體中,資料庫的角色會變得不重要。
- 隨著RAM的普及,資料庫的角色可能會改變,系統架構應該對底層存儲技術保持中立。
資料模型對系統架構重要,而資料庫只是技術細節。
性能是考量標準,但應該在數據訪問層面解決,而非系統架構層面。

原文翻譯
從架構的角度來看,資料庫並不是一個實體——它只是個細節,並沒有達到架構元素的層級。它與軟體系統架構的關係,就像門把手與房屋架構的關係。
我知道這些話可能會引起爭議。相信我,我已經爭論過很多次了。所以我要說清楚:我不是在討論資料模型。應用程式中的資料結構對系統架構來說非常重要,但資料庫不是資料模型。資料庫只是一款軟體,是用來存取資料的工具。從架構的角度來看,這個工具是無關緊要的,因為它只是個底層的實現細節。一個好的架構師不會讓底層機制污染系統架構。
關聯式資料庫
Edgar Codd 在 1970 年定義了關聯式資料庫的原理。到了 1980 年代中期,關聯模型成為主要的資料儲存形式。這種流行是有原因的:關聯模型優雅、自律且穩健,是一種優秀的資料儲存與存取技術。
但無論這種技術多麼出色、有用且符合數學原理,它仍然只是一種技術,也就是說,它終究只是個細節。
雖然關聯表格在某些數據存取形式上可能很方便,但將數據排列成表格中的行並沒有任何架構上的重要性。你的應用程式的使用案例不應該知道或關心這些問題。事實上,對數據表格結構的了解應該限制在架構外圍的最低層級的工具函數中。
許多數據存取框架允許將資料庫的行和表格作為物件在系統中傳遞。允許這樣做是一個架構上的錯誤。這會將使用案例、業務規則,甚至在某些情況下,將使用者介面與數據的關聯結構耦合在一起。
資料庫系統為什麼如此普遍?
圖表
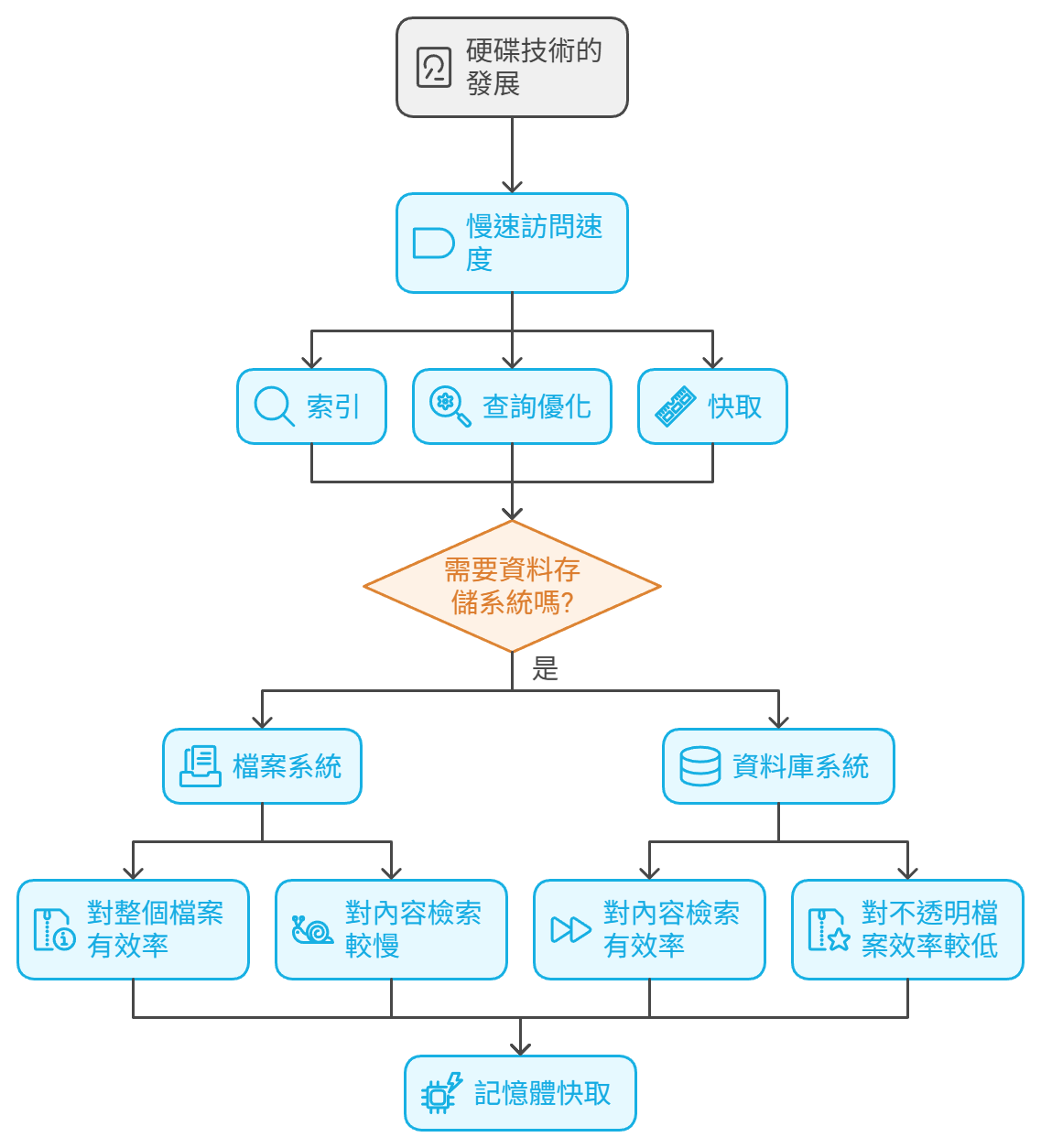
為什麼資料庫系統在軟體系統和企業軟體領域如此流行?Oracle、MySQL 和 SQL Server 這些產品廣泛流行的原因是什麼?答案是硬碟。
帶有高速旋轉的磁盤,以磁感應方式讀取數據的硬碟在過去五十年成為數據存儲的主流手段,以至於最近幾代程式設計師對其他類型的數據存儲幾乎一無所知。而且硬碟技術一直在發展,硬碟技術從直徑 48 英吋、重達數千磅、容量僅 20 兆字節的巨大碟片堆疊,發展到直徑 3 英吋、重量僅幾克的薄薄一張單片薄圓片的硬碟就能存儲上 TB 的數據。這發展得實在是太快了!但是在硬碟的整個發展過程中,程式設計師們始終被一個限制困擾著:磁碟的訪問速度太慢了!
在磁碟上,數據是按照環形軌道存儲的。這些軌道又會進一步被劃分成一系列扇區,這些扇區的大小通常是 4 KB。而每個盤片上都有幾百條軌道,整個硬碟可能由十幾個盤片組成。如果要從硬碟上讀取某一個特定字節,需要將磁頭移到正確的軌道上,等待盤片旋轉到正確的位置上,再將整個扇區讀入內存中,從內存中查詢對應的字節。這些過程當然需要時間,所以硬碟的訪問速度一般在毫秒級。
毫秒級的速度看起來好像並不是很慢,但這已經比大多數處理器的速度慢一百萬倍了。如果數據不在硬碟上,訪問速度通常就是納秒級,而不是毫秒級了。
為了應對硬碟訪問速度帶來的限制,必須使用索引、快取以及查詢優化器等技術。同時,我們還需要一種數據的標準展現格式,以便讓索引、快取及查詢優化器來使用。概括來說,我們需要的就是某種數據訪問與管理系統。過去幾十年內,業界逐漸發展出了兩種截然不同的系統:檔案系統與關聯式資料庫管理系統(RDBMS)。
檔案系統是基於文件格式的,它提供了一種便於存儲整個文件的方式。當需要按照名字存儲數據和查找一系列文件時,檔案系統很有用,但當我們需要檢索文件內容時,它就沒那麼有用了。也就是說,我們在檔案系統中查找一個名字為 login.c 的文件很容易,但要檢索出所有包括變數 x 的 .c 文件就很困難,速度也很慢。
而資料庫系統則主要關注的是內容,它提供了一種便於進行內容檢索的存儲方式。其最擅長的是根據某些共同屬性來檢索一系列記錄。然而,它對存儲和訪問內容不透明的文件的支持就沒那麼強了。
這兩種系統都是為了優化磁碟存儲而設計的,人們需要根據它們的特點來將數據組織成最便於訪問的模式。每個系統都有一套索引和安排數據的方式。同時,每種系統最終都會將數據快取在記憶體中,方便快速操作。
這些技術限制使得資料庫系統成為了優化資料存取性能的必要工具,從而在軟體系統和企業中變得如此普遍。
假設磁碟不存在會怎樣?
雖然硬碟現在還是很常見,但其實已經在走下坡路了。很快它們就會和磁帶、軟碟、CD 一樣成為歷史,RAM 正在替代一切。
現在,我們要來考慮一下:如果所有的數據都存在記憶體中,應該如何組織它們呢?需要按表格存儲並且用 SQL 查詢嗎?需要用文件形式存儲,然後按目錄查找嗎?
事實上,如果你再仔細想想,就會發現我們已經在這樣做了。即使數據保存在資料庫或者檔案系統中,我們最終也會將其讀取到記憶體中,並按照最方便的形式將其組織成列表、集合、堆疊、佇列、樹等各種數據結構,繼續按文件和表格的形式來操作數據是非常少見的。
實現細節
這就是為什麼我們認為資料庫只是一種實現細節的原因。資料庫終究只是在硬碟與記憶體之間相互傳輸數據的一種手段而已,它真的可以被認為只是一個長期存儲數據的、裝滿位元組的大桶。我們通常並不會真的以這種形式來使用數據。
因此,從系統架構的視角來看,真的不應該關心數據在旋轉的磁碟表面上以什麼樣的格式存在。實際上,系統架構應該對磁碟本身的存在完全不關心。
但性能呢?
性能難道不是系統架構的一個考量標準嗎?當然是——但當問題涉及數據存儲時,這方面的操作通常是被封裝起來,隔離在業務邏輯之外的。也就是說,我們確實需要從數據存儲中快速地存取數據,但這終究只是底層實現問題。我們完全可以在數據訪問這一較低的層面上解決這個問題,而不需要讓它與系統架構相關聯。
一段軼事
圖表
在 20 世紀 80 年代末,我曾在一家創業公司中帶領一組軟體工程師開發和推廣一個用於監控 T1 線路通信質量的網絡管理系統。該系統從 T1 線路兩端的設備抓取數據,然後利用預測算法來檢測和匯報問題。
我們當時採用的是 UNIX 平台,並將數據存儲成簡單的可隨機訪問的格式。該項目當時也不需要用到關係型數據庫,因為數據之間幾乎沒有內容之間的關係,用樹以及鏈表的形式來存儲數據就夠了。簡單來說,我們的數據存儲格式是為了便於加載到記憶體中處理而設計的。
創業公司後來招聘了一個市場推廣經理。他人很好,知識也很全面。然而他告訴我的第一件事就是我們系統中必須有一個關係型數據庫。這容不得商量,也不是一個工程問題——而是一個市場問題。
這對我來說很難接受,為什麼我要將鏈表和樹重新按照表格與行模式重組,並且用 SQL 方式存儲呢?為什麼我們要在隨機訪問文件系統已經足夠用的情況下引入大型關係型數據庫系統?所以我一直和他針鋒相對,互不相讓。
後來公司內有一位硬體工程師被關係型數據庫大潮所感染:他堅信我們的軟體系統在技術上有必要採用關係型數據庫,他背著我召集了公司的管理層開會,在白板上畫了一間用幾根杆子支撐的房子,問道:「誰會把房子建在幾根杆子搭起來的地基上?」這背後的邏輯是:通過關係型數據庫將數據存儲於文件系統中,在某種程度上要比我們自己存儲這些文件更可靠。
我當然沒有放棄,一直不停地和他還有市場部鬥爭到底。我誓死捍衛了自己的工程原則,不停地開會、鬥爭。
最終,這位硬體工程師被提拔為軟體開發經理,最終,系統中也加入了一個關係型數據庫。最終,我不得不承認,他們是對的,而我是錯的。
這裡說的不是軟體工程問題:在這個問題上我仍然堅持自己沒有錯,在系統的核心架構中的確不應該引入關係型數據庫。這裡說我錯了的原因,是因為我們的客戶希望該系統中能有一個關係型數據庫。他們其實也不知道為什麼需要,因為他們自己是沒有任何機會使用這個關係型數據庫的。但這不是重點,問題的重點是我們的客戶需要一個關係型數據庫。它已經成為當時所有軟體購買合同中的一個必選項。這背後毫無工程邏輯——是不理智的。但儘管它是不理智的、外行的、毫無根基的需求,但卻是真實存在的。
這種需求是從哪裡來的?其實是來自於當時數據庫廠商非常有效的市場推廣。他們說服了企業高管,他們的“數據資產”需要某種保護,數據庫則提供了非常便捷的保護能力。
直到今天我們也能看到這種市場宣傳,例如“企業級”“面向服務的架構”這樣的措辭大部分都是市場宣傳噱頭,而跟實際的工程質量無關。
回頭想想,我在這個場景中應該怎麼做呢?事實上,我當時應該在系統的某個角落接上一個關係型數據庫,在維持系統核心數據結構的同時給關係型數據庫提供一些安全的、受限的數據訪問方式。但我沒這麼做,我辭職了,幹起了諮詢這一行。
本章小结
資料的組織結構,即資料模型,是系統架構中非常重要的一部分。而從旋轉磁碟上存取資料的技術和系統則沒那麼重要。關聯式資料庫系統強制我們將資料組織成表格並使用 SQL 存取,這更多是關於後者而非前者。資料本身是重要的,而資料庫只是個細節。