當資料的格式(format)或模式(schema)發生變化時,通常需要對應用程式程式碼進行相應的更改(例如,為記錄新增新欄位,然後修改程式開始讀寫該欄位)。但在大型應用程式中,程式碼變更通常不會立即完成:
| 服務端(server-side): | 可能需要執行 滾動升級(rolling upgrade),一次將新版本部署到少數幾個節點,檢查新版本是否執行正常,然後逐漸部完所有的節點。 |
| 客戶端(client-side): | 升不升級就要看使用者的心情了。使用者可能相當長一段時間裡都不會去升級軟體。 |
這也表示,新舊版本的程式碼或是新舊資料格式可能會在系統中同時共處。系統想要繼續順利執行,就需要保持雙向相容性:
| 向後相容(backward compatibility): | 新的程式碼可以讀取由舊的程式碼寫入的資料。較容易處理,因為作者知道舊程式碼所使用的資料格式(一般最簡單的方法,就是保留舊程式碼即可讀取舊資料)。 |
| 向前相容(forward compatibility): | 舊的程式碼可以讀取由新的程式碼寫入的資料。較不易處理,因為舊版的程式需要忽略新版資料格式中新增的部分。 |
編碼資料的格式bo
程式通常(至少)使用兩種形式的資料:
- 資料以物件、結構體、列表、陣列、散列表、樹等方式儲存到記憶體中。這些資料結構針對 CPU 的高效訪問和操作進行了最佳化(通常使用指標)。
- 資料寫入檔案,或透過網路傳送,則必須將其轉換為某種自包含的位元組序列(例如,JSON 文件)。這個位元組序列表示會與通常在記憶體中使用的資料結構不同。
要在兩種表示之間進行某種型別的翻譯。從記憶體中表示到位元組序列的轉換稱為編碼(Encoding)(也稱為序列化(serialization)或編組(marshalling)),反過來稱為解碼(Decoding)2(解析(Parsing),反序列化(deserialization),反編組 (unmarshalling))
語言特定的格式
許多程式語言都內建了將記憶體物件編碼為位元組序列的支援。
- Java 有 java.io.Serializable。
- Ruby 有 Marshal。
- Python 有 pickle。
- 第三方類別庫像是 Kryo for Java ....等。
編碼庫很方便,可以用很少的程式碼實現記憶體物件的儲存與恢復。但也有一些深層次的問題:
- 與特定的程式語言深度繫結,其他語言很難讀取這種資料,且很難將系統與其他組織的系統(可能用的是不同的語言)進行整合。
- 為了恢復相同物件型別的資料,解碼過程需要 例項化任意類。這會有安全性問題,若攻擊者可以讓應用程式解碼任意的位元組序列,他們就能例項化任意的類。
- 容易出現向前向後相容性帶來的麻煩問題。
- 效率(編碼或解碼所花費的 CPU 時間,以及編碼結構的大小)。例如,Java 的內建序列化由於其糟糕的效能和臃腫的編碼而臭名昭著。
JSON、XML和CSV
JSON,XML 和 CSV 屬於文字格式,因此具有人類可讀性。但也存在一些微妙的問題:
- 數字(numbers)編碼有很多模糊之處。在 XML 和 CSV 中,無法區分數字和純數字組成的字串(除了引用外部模式)。JSON 雖然區分字串與數字,但並不區分整數和浮點數,並且不能指定精度。
- 處理大數字時是個問題。例如大於的整數無法使用 IEEE 754 雙精度浮點數精確表示因此在使用浮點數(例如 JavaScript)的語言進行分析時,這些數字會變得不準確。
- JSON 和 XML 不支援二進位制資料(即不帶 字元編碼(character encoding)的位元組序列)。
- XML 和 JSON 都有可選的模式支援。這些模式語言相當強大,相對學習和實現起來都比較複雜。
- CSV 沒有任何模式,因此每行和每列的含義完全由應用程式自行定義。如果應用程式變更添加了新的行或列,那麼這種變更必須透過手工處理。
二進位制編碼
小資料集合的編碼造成的效能影響可以忽略不計;但一旦達到 TB 級別,資料格式的選型就會產生巨大的影響。二進位制串是很有用的功能,人們透過使用 Base64 將二進位制資料編碼為文字來繞過此限制。其特有的模式標識著這個值應當被解釋為 Base64 編碼的二進位制資料。
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
MessagePack
下圖為 MessagePack 編碼後的格式定義:
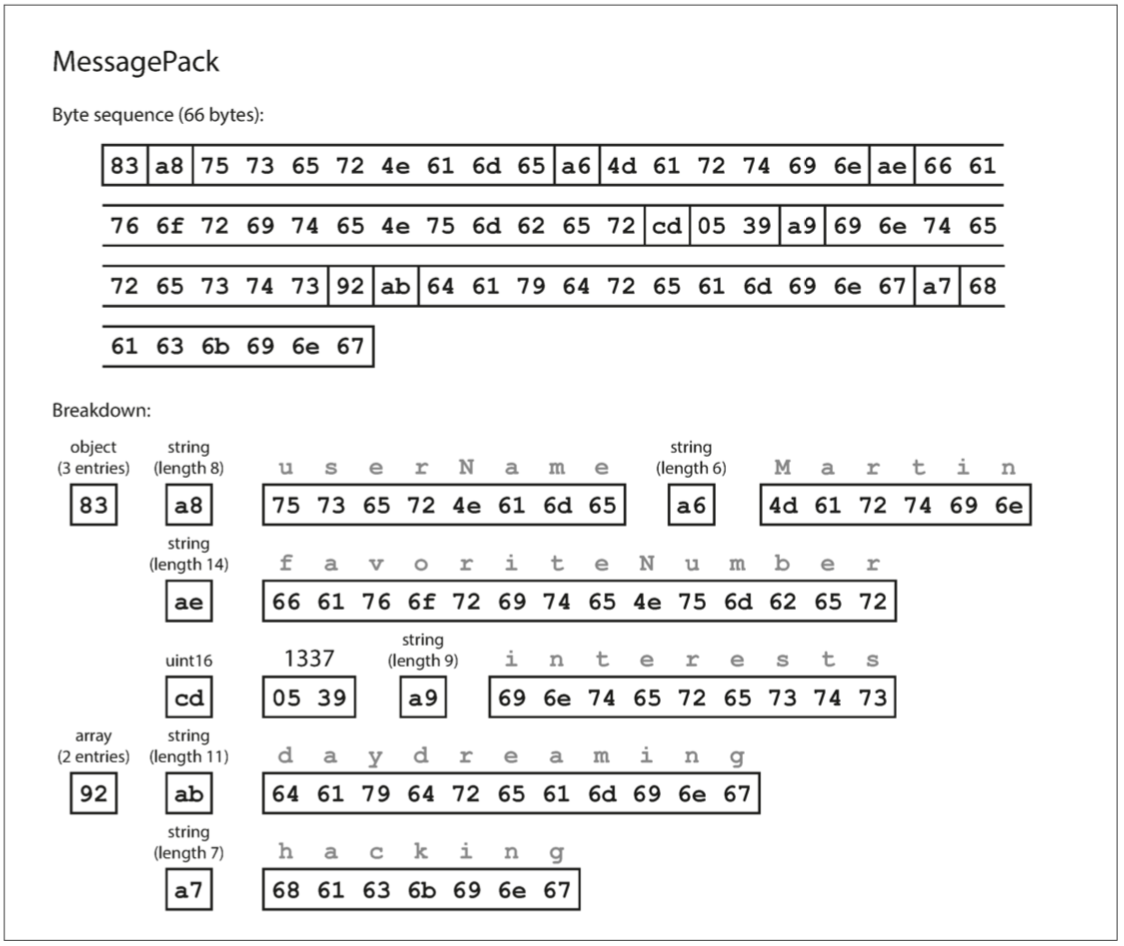
- 第 1 個位元組為 83(1000 0011),1000 表示資料型別為 fixmap,0011 表示有 3 個項目。
- 第 2 ~ 10 個位元組表示欄位 "userName"。
- 第 2 個位元組為 a8(1010 1000),101 表示資料型別為 fixstr,01000 表示長度為 8。
- 第 3 ~ 10 個位元組表示 userName 的 ASCII 編碼。
- 第 11 ~ 17 個位元組表示值 "Martin"。
- 第 18 ~ 32 個位元組表示欄位 "favoriteNumber"。
- 第 33 ~ 35 個位元組表示值 1337。
- 第 33 個位元組為 cd(1100 1101),表示資料型別為 uint16。
- 第 34 ~ 35 表示 1337(05 39) 的十六進制編碼。
- 第 36 ~ 45 個位元組表示欄位 "interests"。
- 第 46 ~ 66 個位元組表示為一個陣列集合的資料。
- 第 46 個位元組為 92(1001 0010),1001 表示資料型別為 fixarray,0010 表示有 2 個項目。
- 第 47 ~ 58 個位元組表示值 "daydreaming"。
- 第 59 ~ 66 個位元組表示值 "hacking"。
詳細教學可參考MessagePack官網。
Thrift
下圖為 Thrift BinaryProtocol 編碼後的格式定義:
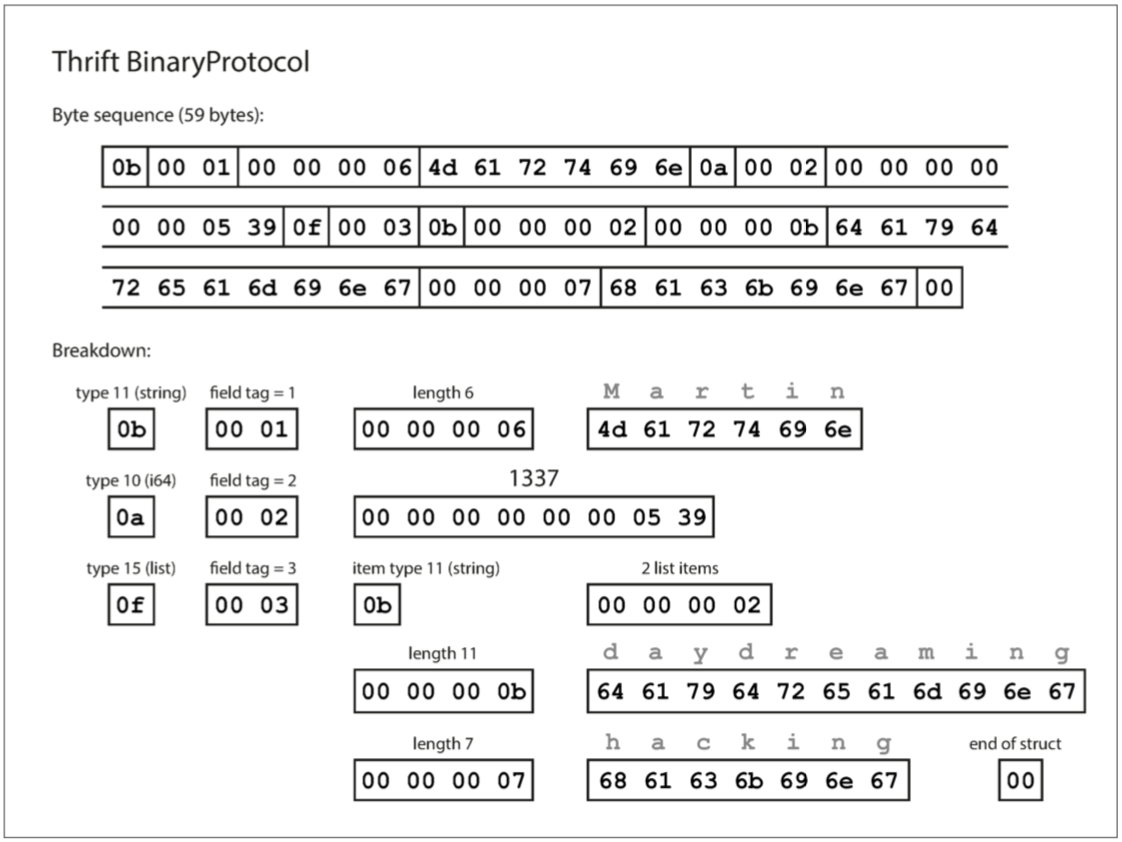
- 第 1 ~ 13 個位元組表示值 "Martin"。
- 第 1 個位元組為 0b 表示為資料型別為 string。
- 第 2 ~ 3 個位元組為 00 01 表示為第 1 個項目。
- 第 4 ~ 7 個位元組為 00 00 00 06 表示為長度為 6。
- 第 8 ~ 13 個位元組表示 Martin 的 ASCII 編碼。
- 第 14 ~ 24 個位元組表示值 1337。
- 第 14 個位元組為 0a 表示為資料型別為 int64。
- 第 15 ~ 16 個位元組為 00 02 表示為第 2 個項目。
- 第 17 ~ 24 個位元組表示 1337 的十六進制編碼。
- 第 25 ~ 59 個位元組表示 1 個陣列集合。
- 第 25 個位元組為 0f 表示為資料型別為 list。
- 第 26 ~ 27 個位元組為 00 03 表示為第 3 個項目。
- 第 28 個位元組為 0b 表示為集合內的資料型別為 string。
- 第 29 ~ 32 個位元組為 00 00 00 02 表示集合含有 2 個項目。
- 第 33 ~ 36 個位元組為 00 00 00 0b 表示為長度為 11。
- 第 37 ~ 47 個位元組為 daydreaming 的 ASCII 編碼。
- 第 48 ~ 51 個位元組為 00 00 00 07 表示為長度為 7。
- 第 52 ~ 58 個位元組為 hacking 的 ASCII 編碼。
- 第 59 個位元組為此集合的結束標記。
詳細教學可參考Thrift Binary protocol encoding。
下圖為 Thrift CompactProtocol 編碼後的格式定義:
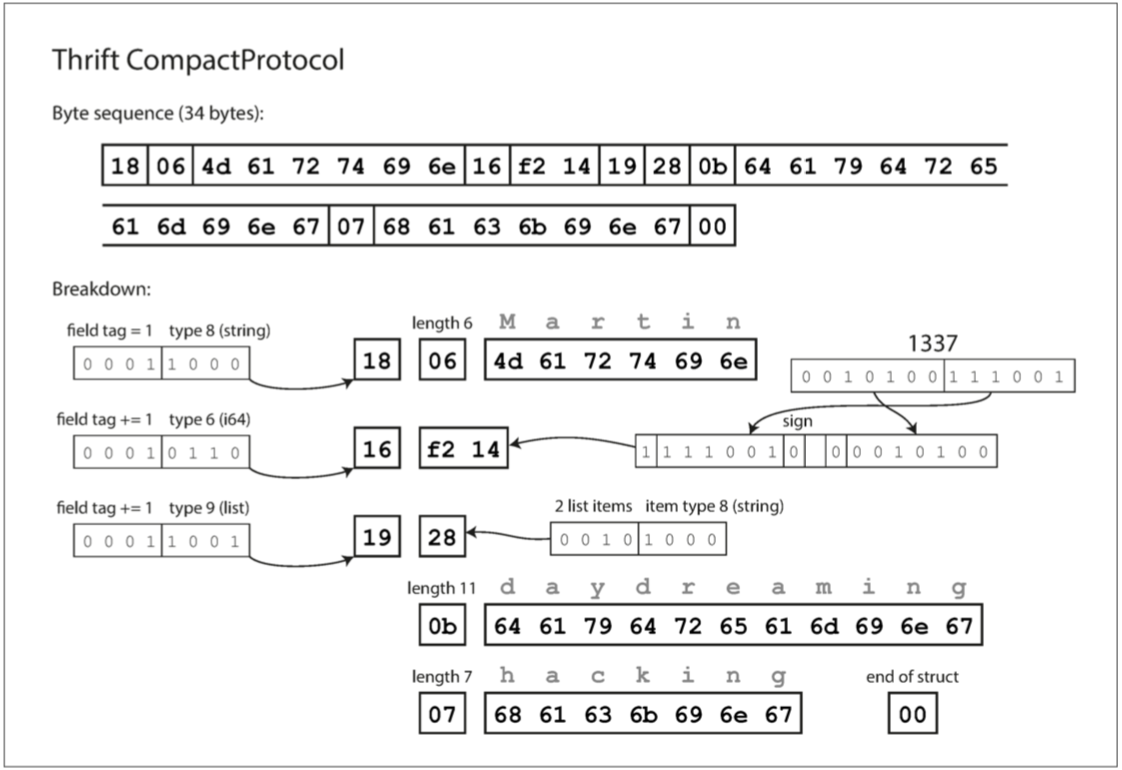
- 第 1 ~ 8 個位元組表示值 "Martin"。
- 第 1 個位元組為 18(0001 1000)。0001 表示 1 個項目,1000 表示為資料型別為 string。
- 第 2 個位元組為 06 表示為長度為 6。
- 第 3 ~ 8 個位元組表示 Martin 的 ASCII 編碼。
- 第 9 ~ 11 個位元組表示值 1337。
- 第 9 個位元組為 16(0001 0110)。0001 表示 1 個項目,0110 表示為資料型別為 int64。
- 第 10 ~ 11 個位元組表示 1337 的十六進制編碼(先作 ZigZag,再作 varint)。
- 第 12 ~ 34 個位元組表示值一個陣列集合。
- 第 12 個位元組為 19(0001 1001)。0001 表示 1 個項目,1001 表示為資料型別為 list。
- 第 13 個位元組為 28(0010 1000)。0010 表示 2 個項目,1000 表示為資料型別為 string。
- 第 14 ~ 25 個位元組表示 daydreaming 的長度 及 ASCII 編碼。
- 第 26 ~ 33 個位元組表示 hacking 的長度 及 ASCII 編碼。
- 第 34 個位元組為此集合的結束標記。
詳細教學可參考Thrift Compact protocol encoding。
Protocol Buffers
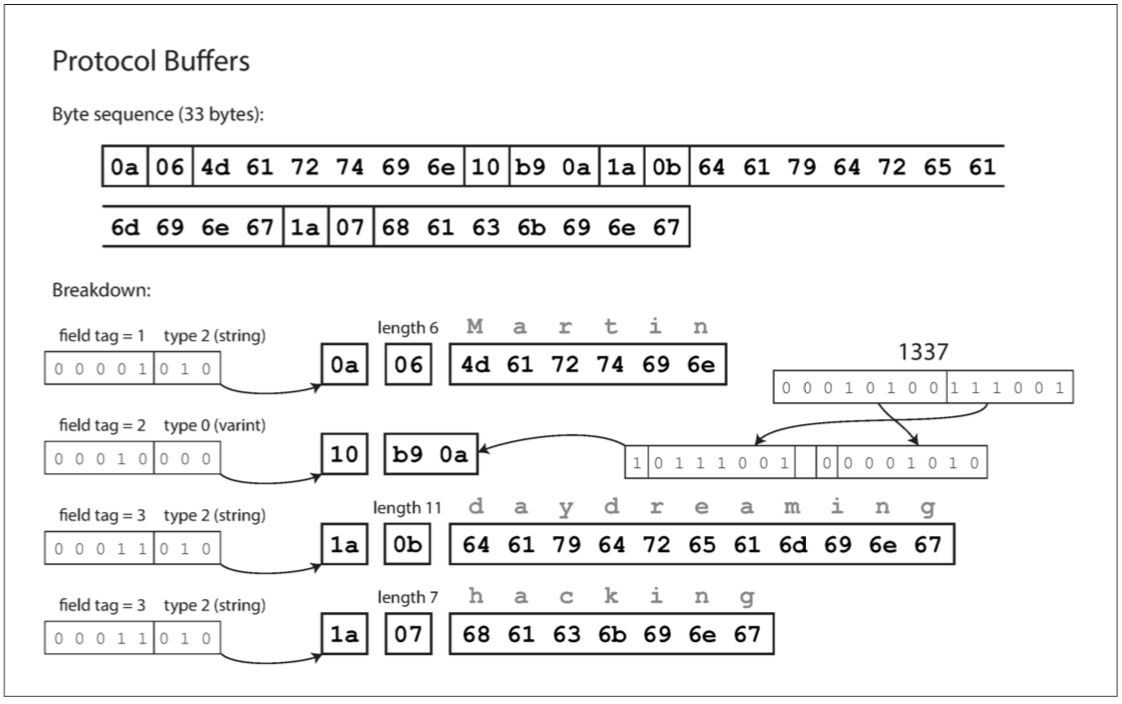
下圖為 Protocol Buffers 編碼後的格式定義:
Avro
下圖為 Thrift CompactProtocol 編碼後的格式定義:
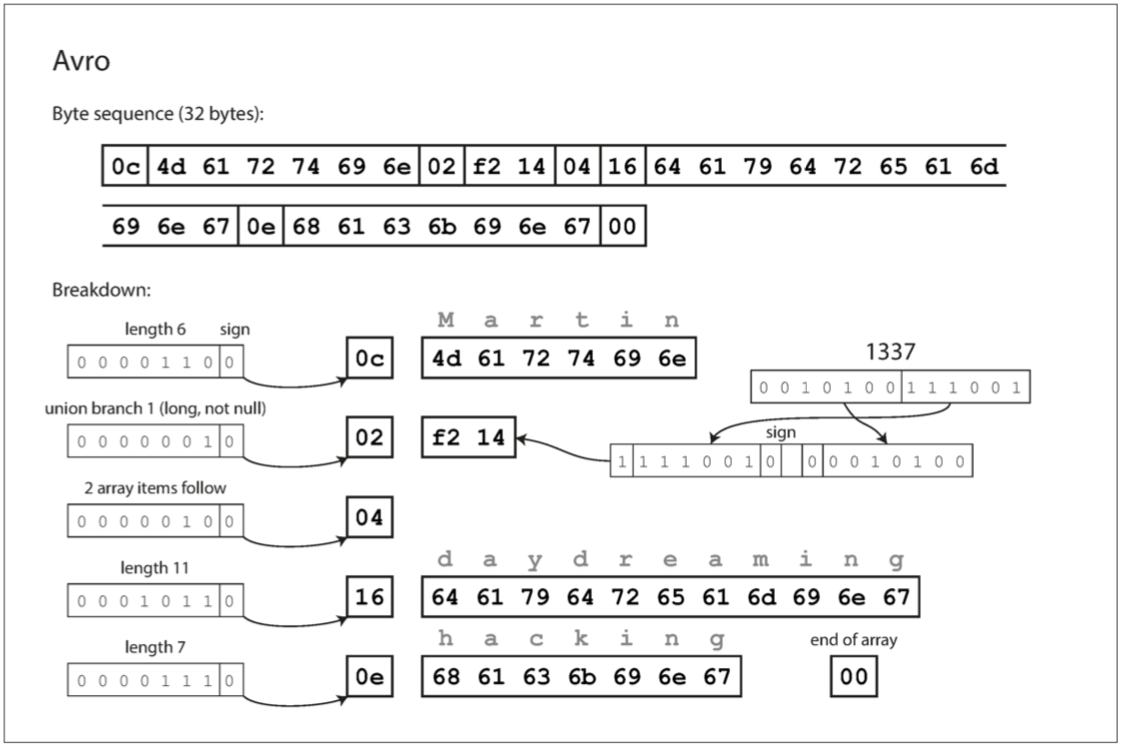
Writer模式與Reader模式
| Writer 模式: | 應用程式想要編碼一些資料(將其寫入檔案或資料庫,透過網路傳送等)時,它使用它知道的任何版本的模式編碼資料。 |
| Reader 模式: | 應用程式想要解碼一些資料(從一個檔案或資料庫讀取資料,從網路接收資料等)時,它希望資料在某個模式中。 |
Avro 的關鍵思想是 Writer 模式和 Reader 模式不必是相同的 - 他們只需要相容。當資料解碼(讀取)時,Avro 庫透過並排檢視 Writer 模式和 Reader 模式並將資料從 Writer 模式轉換到 Reader 模式來解決差異。
Writer 模式和 Reader 模式的欄位順序不同,這是沒有問題的,因為模式解析透過欄位名匹配欄位。如果讀取資料的程式碼遇到出現在 Writer 模式中但不在 Reader 模式中的欄位,則忽略它。如果讀取資料的程式碼需要某個欄位,但是 Writer 模式不包含該名稱的欄位,則使用在 Reader 模式中宣告的預設值填充。
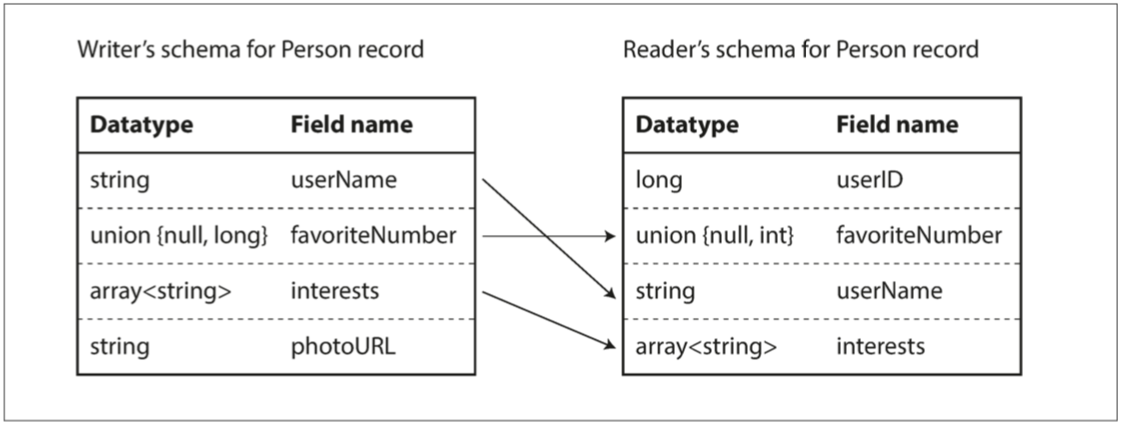
Writer模式到底是什麼
對於一段特定的編碼資料,Reader 如何知道其 Writer 模式?這取決於 Avro 使用的上下文。例如:
- 有很多記錄的大檔案。
- 支援獨立寫入的記錄的資料庫。
- 透過網路連線傳送記錄。
模式的優點
- 可以比各種 “二進位制 JSON” 變體更緊湊,因為它們可以省略編碼資料中的欄位名稱。
- 模式是一種有價值的文件形式,因為模式是解碼所必需的,所以可以確定它是最新的。
- 維護一個模式的資料庫允許你在部署任何內容之前檢查模式更改的向前和向後相容性。
- 對於靜態型別程式語言的使用者來說,從模式生成程式碼的能力是有用的,因為它可以在編譯時進行型別檢查。
資料流的型別
想要將某些資料傳送到不共享記憶體的另一個程序,就需要將它編碼為一個位元組序列。而資料可以透過多種方式從一個流程流向另一個流程,下列是一些常見的方式:
- 透過資料庫(詳細參閱 資料庫中的資料流)。
- 透過服務呼叫(詳細參閱 服務中的資料流:REST與RPC)。
- 透過非同步訊息傳遞(詳細參閱 訊息傳遞中的資料流)。
資料庫中的資料流
在資料庫中,寫入資料庫的過程對資料進行編碼,從資料庫讀取的過程對資料進行解碼。假若今天有一個程序訪問資料庫,在這種情況下,當程序更新為後續版本,就必須考慮將資料庫中的內容儲存為能向未來的自身程序傳送訊息。因此向後相容性顯然是必要的,否則你未來的程序將無法解碼你以前程序的資料。
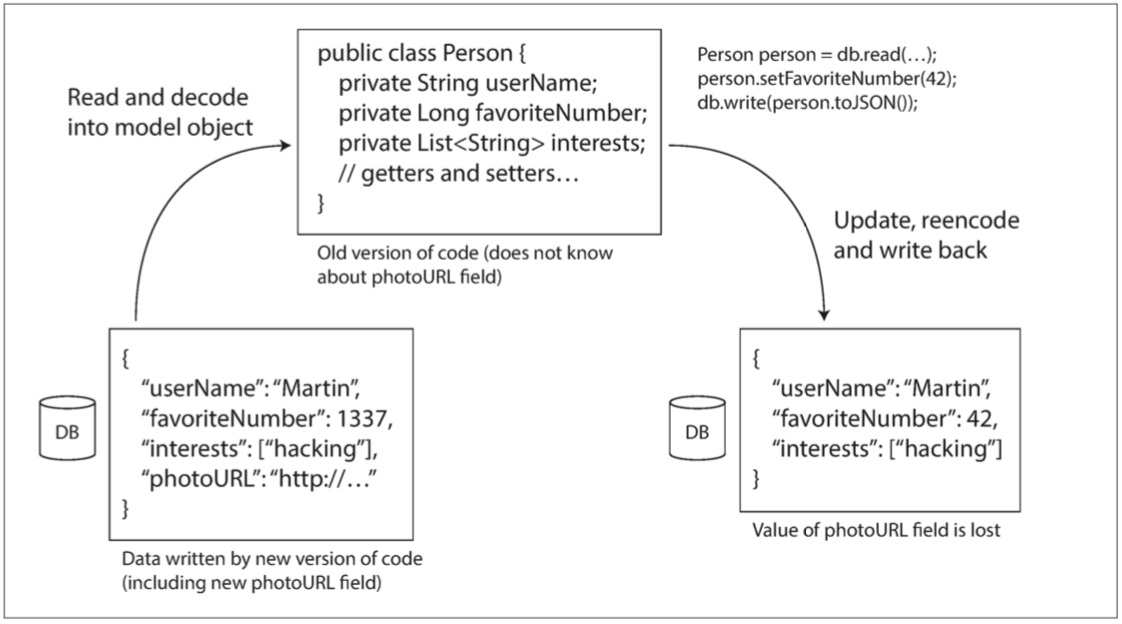 當較舊版本的應用程式更新以前由較新版本的應用程式編寫的資料時,如果不小心,資料可能會丟失。
當較舊版本的應用程式更新以前由較新版本的應用程式編寫的資料時,如果不小心,資料可能會丟失。
在不同的時間寫入不同的值
資料庫通常允許任何時候更新任何值。這意味著在一個單一的資料庫中,可能有一些值是五毫秒前寫的,而一些值是五年前寫的。
將資料重寫(遷移)到一個新的模式當然是可能的,但是在一個大資料集上執行是一個昂貴的事情,所以大多數資料庫如果可能的話就避免它。大多數關係資料庫都允許簡單的模式更改,例如新增一個預設值為空的新列,而不重寫現有資料。讀取舊行時,對於磁碟上的編碼資料缺少的任何列,資料庫將填充空值。
因此,模式演變允許整個資料庫看起來好像是用單個模式編碼的,即使底層儲存可能包含用各種歷史版本的模式編碼的記錄。
歸檔儲存
也許你不時為資料庫建立一個快照,例如備份或載入到資料倉庫。在這種情況下,即使源資料庫中的原始編碼包含來自不同時代的模式版本的混合,資料轉儲通常也將使用最新模式進行編碼。既然你不管怎樣都要複製資料,那麼你可以對這個資料複製進行一致的編碼。
由於資料轉儲是一次寫入的,而且以後是不可變的,所以 Avro 物件容器檔案等格式非常適合。這也是一個很好的機會,可以將資料編碼為面向分析的列式格式,例如列壓縮(Parquet)。
服務中的資料流:REST與RPC
透過網路進行通訊的方式最常見的安排兩個角色:
| 伺服器: | 透過網路公開 API,也就是所謂的服務。 |
| 客戶端: | 可以連線到伺服器以向該 API 發出請求。 |
Web 以這種方式工作:客戶(Web 瀏覽器)向 Web 伺服器發出請求,透過 GET 請求下載 HTML、CSS、JavaScript、影象等,並透過 POST 請求提交資料到伺服器。
API 則包含一組標準的協議和資料格式(HTTP、URL、SSL/TLS、HTML 等)。由於網路瀏覽器、網路伺服器和網站作者大多同意這些標準,因此可以使用任何網路瀏覽器訪問任何網站。
也由於 Web 瀏覽器不是唯一的客戶端型別,所以伺服器的響應通常不是用於顯示給人的 HTML,而是便於客戶端應用程式進一步處理的編碼資料(例如 JSON)。雖然 HTTP 可能被用作傳輸協議,但頂層實現的 API 是特定於應用程式的,客戶端和伺服器需要就該 API 的細節達成一致。
伺服器本身可以是另一個服務的客戶端(例如,典型的 Web 應用伺服器充當資料庫的客戶端)。這種方法通常用於將大型應用程式按照功能區域分解為較小的服務,這樣當一個服務需要來自另一個服務的某些功能或資料時,就會向另一個服務發出請求。這種構建應用程式的方式傳統上被稱為面向服務的體系結構(service-oriented architecture,SOA),最近被改進和更名為微服務架構。
這類服務類似於資料庫,它們通常允許客戶端提交和查詢資料。並公開了一個特定於應用程式的 API,只允許由服務的業務邏輯(應用程式程式碼)預定的輸入和輸出。這種限制提供了一定程度的封裝,限制了對客戶可以做什麼和不可以做什麼。面向服務 / 微服務架構的設計目標是使服務獨立部署來讓應用程式更易於更改和維護。每個服務應該由一個開發團隊擁有,而不必與其他團隊協調,因此伺服器和客戶端使用的資料編碼必須在不同版本的服務 API 之間相容。
Web服務
服務使用 HTTP 作為底層通訊協議時,可稱之為 Web 服務。它不僅在 Web 上使用,而且在幾個不同的環境中使用:
- 執行在使用者裝置上的客戶端應用程式,透過 HTTP 向服務發出請求。
- 一個服務向同一組織擁有的另一個服務提出請求,這些服務通常位於同一資料中心內,作為面向服務 / 微服務架構的一部分。(支援這種用例的軟體有時被稱為中介軟體(middleware))
- 一個服務透過網際網路向不同組織所擁有的服務提出請求。這用於不同組織後端系統之間的資料交換。此類別包括由線上服務(如信用卡處理系統)提供的公共 API,或用於共享訪問使用者資料的 OAuth。
兩種流行的 Web 服務方法:
| REST: | 是一個基於 HTTP 原則的設計。強調簡單的資料格式,使用 URL 來標識資源,並使用 HTTP 功能進行快取控制,身份驗證和內容型別協商。 |
| SOAP: | 用於製作網路 API 請求,使用稱為 Web 服務描述語言(WSDL,詳細教學可參考WSDL教學)的基於 XML 的協議。WSDL 支援程式碼生成,客戶端可以使用本地類和方法呼叫(編碼為 XML 訊息並由框架再次解碼)訪問遠端服務。雖然它最常用於 HTTP,但其目的是獨立於 HTTP,並避免使用大多數 HTTP 功能。 |
WSDL文件範例如下:
<definitions name = "HelloService"
targetNamespace = "http://www.examples.com/wsdl/HelloService.wsdl"
xmlns = "http://schemas.xmlsoap.org/wsdl/"
xmlns:soap = "http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:tns = "http://www.examples.com/wsdl/HelloService.wsdl"
xmlns:xsd = "http://www.w3.org/2001/XMLSchema">
<message name = "SayHelloRequest">
<part name = "firstName" type = "xsd:string"/>
</message>
<message name = "SayHelloResponse">
<part name = "greeting" type = "xsd:string"/>
</message>
<portType name = "Hello_PortType">
<operation name = "sayHello">
<input message = "tns:SayHelloRequest"/>
<output message = "tns:SayHelloResponse"/>
</operation>
</portType>
<binding name = "Hello_Binding" type = "tns:Hello_PortType">
<soap:binding style = "rpc"
transport = "http://schemas.xmlsoap.org/soap/http"/>
<operation name = "sayHello">
<soap:operation soapAction = "sayHello"/>
<input>
<soap:body
encodingStyle = "http://schemas.xmlsoap.org/soap/encoding/"
namespace = "urn:examples:helloservice"
use = "encoded"/>
</input>
<output>
<soap:body
encodingStyle = "http://schemas.xmlsoap.org/soap/encoding/"
namespace = "urn:examples:helloservice"
use = "encoded"/>
</output>
</operation>
</binding>
<service name = "Hello_Service">
<documentation>WSDL File for HelloService</documentation>
<port binding = "tns:Hello_Binding" name = "Hello_Port">
<soap:address
location = "http://www.examples.com/SayHello/" />
</port>
</service>
</definitions>
遠端過程呼叫(RPC)的問題
遠端過程呼叫(RPC)的思想,RPC 模型試圖向遠端網路服務發出請求,看起來與在同一程序中呼叫函式或方法相同。但根本上是有缺陷的。因為網路請求與本地函式呼叫還是有不同之處:
| 本地函式呼叫 | 網路請求 |
|---|---|
| 可預測的,成功或失敗取決於受你控制的引數 | 不可預測的,請求或響應可能由於網路問題會丟失 |
| 返回/不返回結果、丟擲異常 | 返回/不返回結果、丟擲異常、或者因為超時造成返回時已沒有結果 |
| 不會發生響應丟失的情況 | 能會發生請求實際上已經完成,只是響應丟失的情況 |
| 執行時間大致相同 | 執行時間不穩定(會有網路擁塞或者遠端服務超載的問題) |
| 可以高效地將引用(指標)傳遞給本地記憶體中的物件 | 所有引數都需要被編碼成可以透過網路傳送的一系列位元組 |
RPC的當前方向
上述的編碼在基礎上構建了各種 RPC 框架:
- Thrift 和 Avro 帶有 RPC 支援
- gRPC 是使用 Protocol Buffers 的 RPC 實現
- Finagle 也使用 Thrift
- Rest.li 使用 JSON over HTTP。
新一代的 RPC 框架更加明確的是,遠端請求與本地函式呼叫不同。
- Finagle 和 Rest.li 使用 futures(promises)來封裝可能失敗的非同步操作。
- gRPC 支援流,其中一個呼叫不僅包括一個請求和一個響應,還可以是隨時間的一系列請求和響應。
訊息傳遞中的資料流
RPC 和資料庫之間的非同步訊息傳遞系統。
- 與 RPC 類似,因為客戶端的請求(通常稱為訊息)以低延遲傳送到另一個程序。
- 與資料庫類似,不是透過直接的網路連線傳送訊息,而是透過稱為訊息代理(也稱為訊息佇列或面向訊息的中介軟體)的中介來臨時儲存訊息。
與直接 RPC 相比,使用訊息代理有幾個優點:
- 如果收件人不可用或過載,可以充當緩衝區,從而提高系統的可靠性。
- 可以自動將訊息重新發送到先前已經崩潰的程序,從而防止訊息丟失。
- 避免發件人需要知道收件人的 IP 地址和埠號(這在虛擬機器經常出入的雲部署中特別有用)。
- 它允許將一條訊息傳送給多個收件人。
- 將發件人與收件人邏輯分離(發件人只是釋出郵件,不關心使用者)。
與 RPC 相比,差異在於訊息傳遞通訊通常是單向的:傳送者通常不期望收到其訊息的回覆。一個程序可能傳送一個響應,但這通常是在一個單獨的通道上完成的。這種通訊模式是非同步的:傳送者不會等待訊息被傳遞,而只是傳送它,然後忘記它。
訊息代理
訊息代理的使用方式如下:一個程序將訊息傳送到指定的佇列或主題,代理確保將訊息傳遞給那個佇列或主題的一個或多個消費者或訂閱者。在同一主題上可以有許多生產者和許多消費者。
訊息代理通常不會執行任何特定的資料模型 —— 訊息只是包含一些元資料的位元組序列,因此你可以使用任何編碼格式。如果編碼是向後和向前相容的,你可以靈活地對釋出者和消費者的編碼進行獨立的修改,並以任意順序進行部署。
分散式的Actor框架
Actor 模型是單個程序中併發的程式設計模型。邏輯被封裝在 actor 中,而不是直接處理執行緒。actor 通常代表一個客戶或實體,它可能有一些本地狀態(不與其他任何角色共享),它透過傳送和接收非同步訊息與其他角色通訊。不保證訊息傳送:在某些錯誤情況下,訊息將丟失。由於每個角色一次只能處理一條訊息,因此不需要擔心執行緒,每個角色可以由框架獨立排程。分散式的 Actor 框架實質上是將訊息代理和 actor 程式設計模型整合到一個框架中。
三個流行的分散式 actor 框架處理訊息編碼如下:
- Akka 使用 Java 的內建序列化,不提供前向或後向相容性。 但是,你可以用類似 Prototol Buffers 的東西替代它,從而獲得滾動升級的能力。
- Orleans 預設使用不支援滾動升級部署的自定義資料編碼格式;要部署新版本的應用程式,你需要設定一個新的叢集,將流量從舊叢集遷移到新叢集,然後關閉舊叢集。像 Akka 一樣,可以使用自定義序列化外掛。
- Erlang OTP 中,對記錄模式進行更改是非常困難的(儘管系統具有許多為高可用性設計的功能)。 滾動升級是可能的,但需要仔細計劃。 一個新的實驗性的 maps 資料型別(2014 年在 Erlang R17 中引入的類似於 JSON 的結構)可能使得這個資料型別在未來更容易。