引言
- 複製資料的目的:
- 使資料與使用者在地理上接近(減少延遲)
- 提高系統可用性(即使部分故障)
- 提高讀取吞吐量(伸縮讀請求機器數量)
- 複製資料系統的挑戰:
- 假設資料集非常小
- 假設每臺機器可以儲存整個資料集的副本
- 處理資料的變更
- 變更複製演算法:
- 單領導者(single leader)
- 多領導者(multi leader)
- 無領導者(leaderless)
- 複製權衡:
- 同步複製 vs 非同步複製
- 處理失敗的副本
- 複製算法歷史:
- 70 年代研究
- 分散式資料庫變為主流
- 複製延遲問題:
- 最終一致性(eventual consistency)
- 讀己之寫(read-your-writes)
- 單調讀(monotonic read)
領導者與追隨者
- 副本(replica):儲存資料庫複製的節點。
- 確保所有資料落在所有副本上的問題: 向資料庫的寫入操作需要傳播到所有副本。
- 基於領導者的複製(leader-based replication):
- 領導者(leader):負責接收寫入操作。
- 追隨者(followers):負責拉取日誌並更新本地資料庫副本。
- 複製過程:
- 客戶端將寫入請求傳送給領導者。
- 領導者將新資料寫入本地儲存。
- 領導者將資料變更傳送給所有追隨者(複製日誌/變更流)。
- 追隨者按照相同處理順序更新本地資料庫副本。
- 讀取操作:客戶端可以向領導者或任一追隨者進行查詢。
- 基於領導者的複製應用範例:
- 關係資料庫:PostgreSQL(9.0 版本開始)、MySQL、Oracle Data Guard、SQL Server 的 AlwaysOn 可用性組。
- 非關係資料庫:MongoDB、RethinkDB、Espresso。
- 分散式訊息代理:Kafka、RabbitMQ 高可用佇列。
- 網路檔案系統:DRBD 等塊複製裝置。
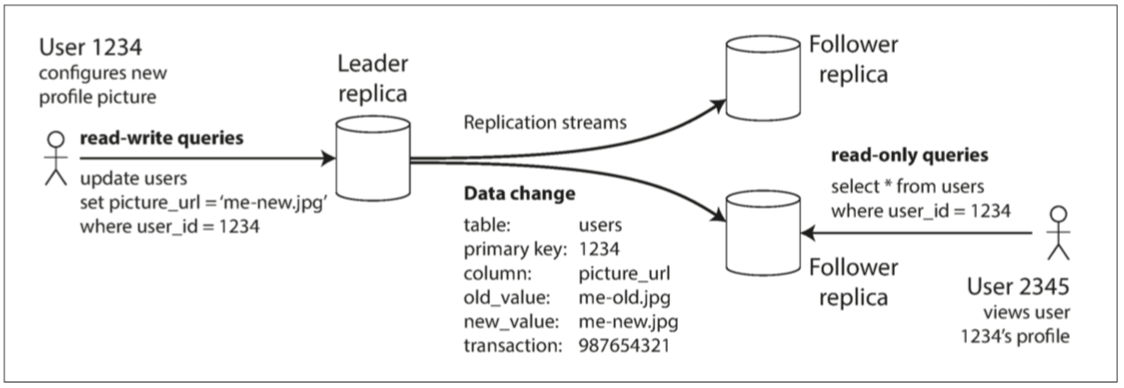
- 圖 5-1 基於領導者的(主/從)複製
同步複製與非同步複製
- 複製細節:複製可以是同步(synchronously)或非同步(asynchronously)。
- 同步複製:主庫在報告寫入成功前,需要等待從庫確認已收到寫入操作。
- 非同步複製:主庫傳送訊息,但不等待從庫響應。
- 同步複製的優缺點:
- 優點:從庫保證有與主庫一致的最新資料副本。
- 缺點:同步從庫無響應時,主庫無法處理寫入操作。
- 半同步複製(semi-synchronous):
- 一個從庫是同步的,其他的從庫則是非同步的。
- 同步從庫不可用或緩慢時,將一個非同步從庫改為同步執行。
- 完全非同步複製:
- 主庫失效且不可恢復時,尚未複製給從庫的寫入會丟失。
- 優點:主庫可以繼續處理寫入,即使所有從庫都落後。
- 鏈式複製(chain replication):
- 同步複製的一種變體,旨在不丟資料並提供良好效能和可用性。
- 已在一些系統中實現,例如 Microsoft Azure Storage。
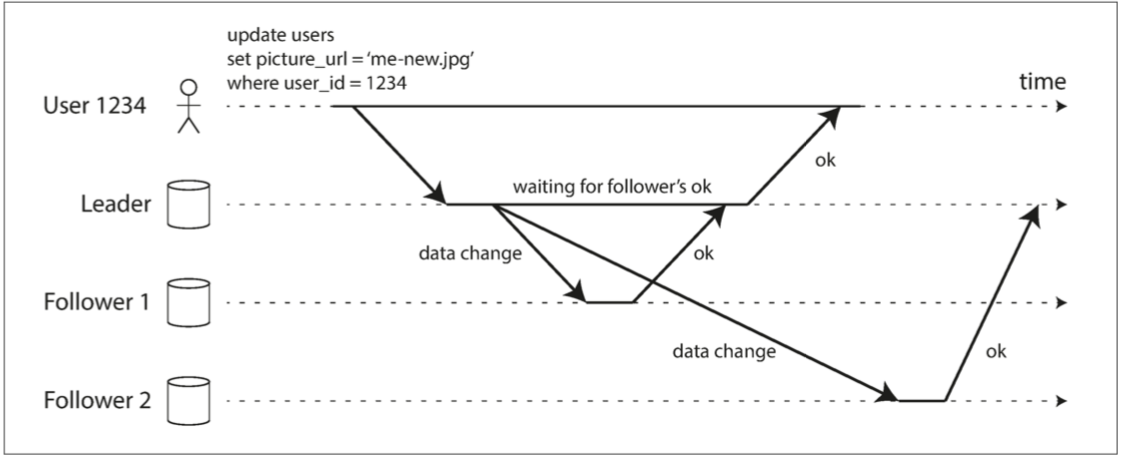
- 圖 5-2 基於領導者的複製:一個同步從庫和一個非同步從庫
- 複製的一致性與共識(consensus):
- 第九章將詳細探討共識理論。
- 本章主要討論實踐中的資料庫常用的簡單複製形式。
- 設定新從節點:
- 獲取主節點一致性快照。
- 將快照複製到新的從節點。
- 從節點連線到主節點並拉取快照後的所有資料變更。
- 從節點趕上主庫後,可以繼續及時處理主節點資料變化。
- 處理節點宕機:
- 以基於領導者的複製實現高可用。
- 從節點失效:追趕恢復
- 重新連線到主節點。
- 請求並處理斷開期間的所有資料變更。
- 主節點失效:故障切換
- 確認主庫失效。
- 選擇新的主節點。
- 重新配置系統以啟用新的主節點。
- 故障切換過程中可能出現的問題:
- 非同步複製導致資料損失。
- 與其他外部儲存協調時的問題。
- 腦裂問題。
- 超時配置的困難。
儘管有些軟體支援自動故障切換,但許多運維團隊仍更願意手動執行故障切換。
- 分散式系統中的基本問題包括節點故障、不可靠的網路、副本一致性、永續性、可用性和延遲。這些問題將在第八章和第九章中深入討論。
- 複製日誌的實現可以分為以下幾種:
- 基於語句的複製:主節點記錄每個寫入請求並將語句日誌傳送給從庫。但這種方式存在諸多問題,如非確定性函式、自增列、副作用等。
- 傳輸預寫式日誌(WAL):主庫將日誌通過網路傳送給從庫。此方法使複製與儲存引擎緊密耦合,升級資料庫軟體可能需要停機。
- 邏輯日誌複製(基於行):對複製和儲存引擎使用不同的日誌格式,使主庫和從庫能夠執行不同版本的資料庫軟體或儲存引擎。邏輯日誌格式更容易解析,有利於資料變更捕獲(change data capture)。
- 基於觸發器的複製:通過資料庫中的觸發器和儲存過程,將資料更改記錄到單獨的表中,再使用外部程式讀取該表並將資料變更複製到另一個系統。儘管開銷較大且容易出錯,但基於觸發器的複製具有很高的靈活性。
以上四種複製方式各有優缺點,具體應用需根據實際情況選擇合適的複製方法。
複製落後的問題
能夠容忍節點故障只是人們採用複製的原因之一。
包括容錯、可伸縮性和降低延遲。 基於領導者的複製方法可用於讀多寫少的場景,通過增加從節點來分散讀請求以達到讀取伸縮。
然而,這種方法主要適用於非同步複製,因為完全同步的配置容易受到節點故障和網路中斷的影響,導致整個系統無法寫入。最後可能會遇到最終一致性問題。
當應用程式讀取從節點時,可能會看到過時的資訊,導致不一致。 這種不一致是暫時的,但在某些情況下,如系統負載過高或網路問題,延遲可能達到幾分鐘。
這不僅是理論問題,還會在應用設計中產生實際影響。 本節將探討複製延遲時可能出現的問題以及解決方案。
讀己之寫
用戶提交資料後可能會立即查看。
然而,如果使用異步複製,新資料可能尚未同步到副本中,導致用戶看不到剛剛提交的資料,造成用戶不滿。
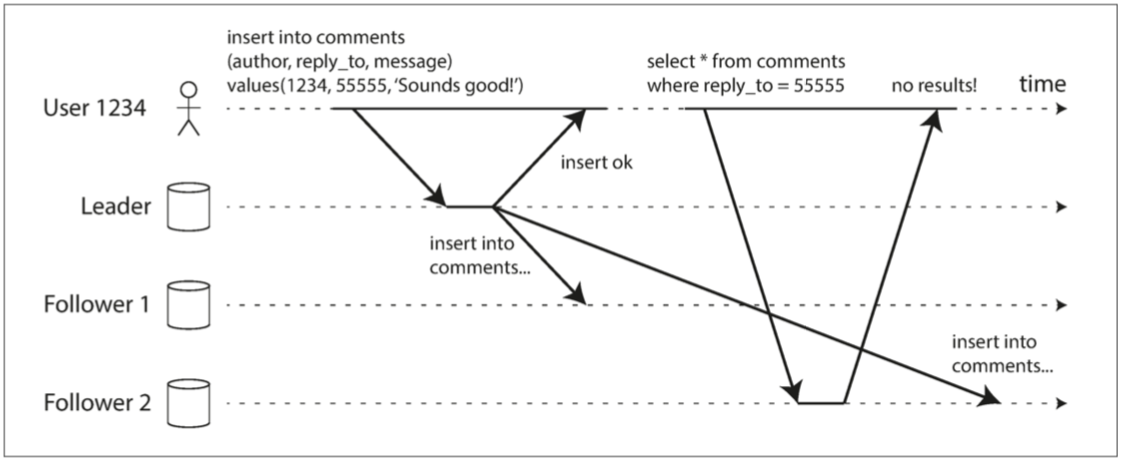
- 圖 5-3 使用者寫入後從舊副本中讀取資料。需要寫後即讀 (read-after-write) 的一致性來防止這種異常
「寫後讀一致性」的概念,它確保用戶在提交更新後重新加載頁面時能看到自己的更新。這並不保證其他用戶立即看到這些更新,但可確保用戶的輸入已被妥善儲存。
在基於領導者的複製系統中實現寫後讀一致性的方法:
- 對可能被使用者修改的內容,總是從主節點讀取。
- 跟蹤上次更新時間,決定是否從主節點讀取。監控從節點的複製延遲,避免讀取過於滯後的從節點。
- 客戶端記住最近一次寫入的時間戳,確保讀取時所有變更已傳播到從節點。
- 考慮數據中心分佈,確保需要主節點的請求路由到正確的資料中心。
使用多個裝置的使用者需提供跨裝置的寫後讀一致性的挑戰。以下是兩個重點:
- 跨裝置元資料的中心化儲存:由於不同裝置上的程式無法知道其他裝置的操作,因此需要對元資料進行中心化儲存,以記住使用者的更新時間戳。
- 跨資料中心的請求路由:當副本分布在不同的資料中心時,確保來自不同裝置的請求路由到同一資料中心變得困難。解決方法是將所有使用者裝置的請求路由到同一個資料中心。
單調讀取
這段描述了在使用非同步從庫讀取資料時,可能出現的時光倒流現象。 當使用者從不同從節點進行多次讀取時,可能會看到不一致的結果,
例如先看到一條評論,然後該評論消失。這種現象可能會讓使用者感到困惑。
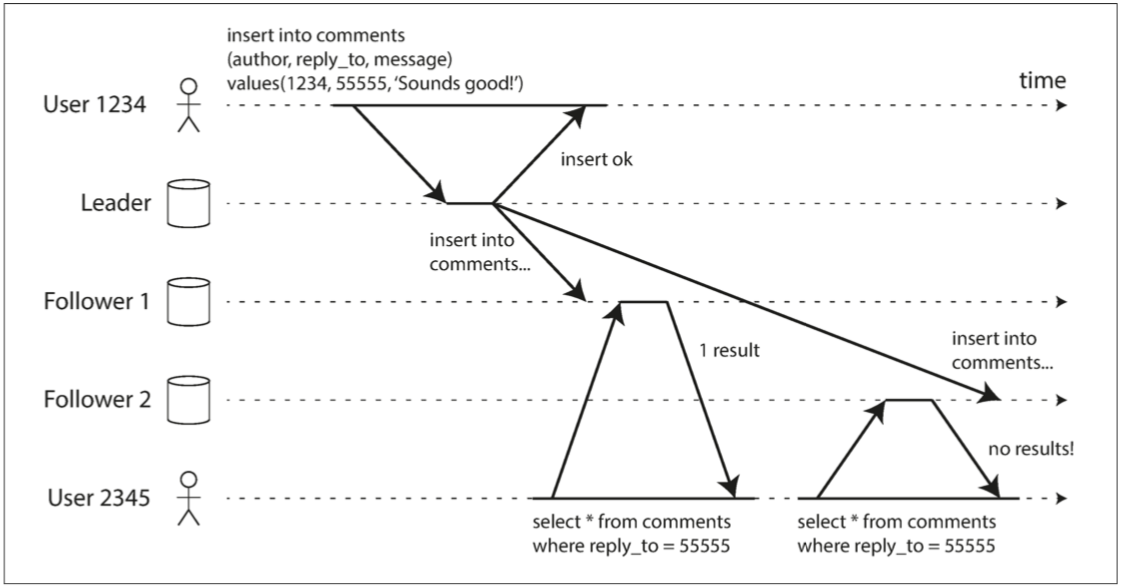
- 圖 5-4 使用者首先從新副本讀取,然後從舊副本讀取。時間看上去回退了。為了防止這種異常,我們需要單調的讀取。
介於強一致性和最終一致性之間的保證。
單調讀確保使用者在連續讀取過程中不會看到時間回退,即使讀取到的是舊資料。 實現單調讀的方法之一是讓每個使用者始終從同一副本讀取資料。
簡單來說,單調讀保證了使用者讀取資料的連續性,避免了時間回退。
一致性前綴讀取
複製延遲異常如何違反因果律。
當第三個人聽到 Cake 夫人和 Poons 先生的對話時,由於從庫延遲的差異,他們聽到的對話順序顛倒了。 這使得觀察者感覺 Cake 夫人在問題被提出之前就已經回答了,顯得具有超能力。
這樣的現象可能會讓人感到困惑。
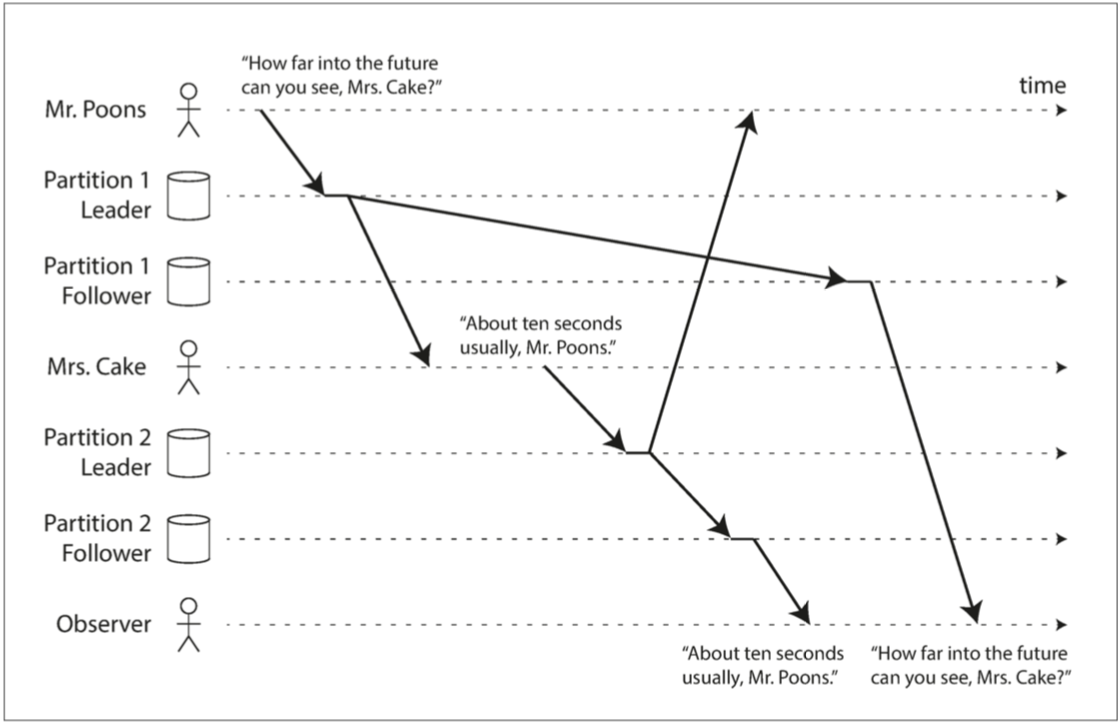
- 圖 5-5 如果某些分割槽的複製速度慢於其他分割槽,那麼觀察者可能會在看到問題之前先看到答案。
系統會為每個寫入操作分配一個全局唯一的時間戳。 這些時間戳保證了操作的全局順序。
當用戶發起讀取請求時,系統會返回小於或等於該請求時間戳的最新數據。 這樣,即使某些節點的數據尚未同步,用戶也能獲得一個一致的數據快照。
此外,這種策略還能保證讀取操作的因果一致性,即用戶能夠觀察到他們之前的寫入操作所引起的變化。
總之,一致性前綴讀取是一種在分布式系統中確保數據讀取一致性的有效策略。 通過使用全局唯一的時間戳對寫入操作進行排序,並在讀取時返回小於或等於請求時間戳的最新數據,這個策略確保了用戶在讀取數據時能夠獲得一個一致的數據快照,同時保證了讀取操作的因果一致性。
複製落後的解決方案
確保資料一致性和正確性非常重要。 當複製延遲變大時,我們需要關注應用程式的行為,確保使用者體驗不受影響。
應用程式可以在資料庫層面提供更強的保證,而事務就是一個很好的解決方案。 儘管在分散式資料庫中,一些系統放棄了事務,但事務仍然是一個有力的工具。
後續章節(第7章、第9章)將更詳細地討論事務和其他替代方案。
多領導複製
目前為止,我們專注在單一主節點的複製架構,但還有其他選擇。單一主節點的問題在於所有寫入都必須通過它,而多領導者配置允許多個節點接受寫入。在這種情況下,每個主節點也同時是其他主節點的從節點。
多領導複製的適用場景
在單個數據中心內部使用多個主節點的配置沒有太大意義,因為其導致的複雜性已經超過了能帶來的好處。但在一些情況下,這種配置也是合理的。
多資料中心操作
討論了一種多主節點配置,用於在多個資料中心分散數據庫副本。這種配置可提高容錯能力和地理親近性。每個資料中心都有一個主庫,並在資料中心之間互相複製更改。這樣可以在本地資料中心內使用常規的主從複製。
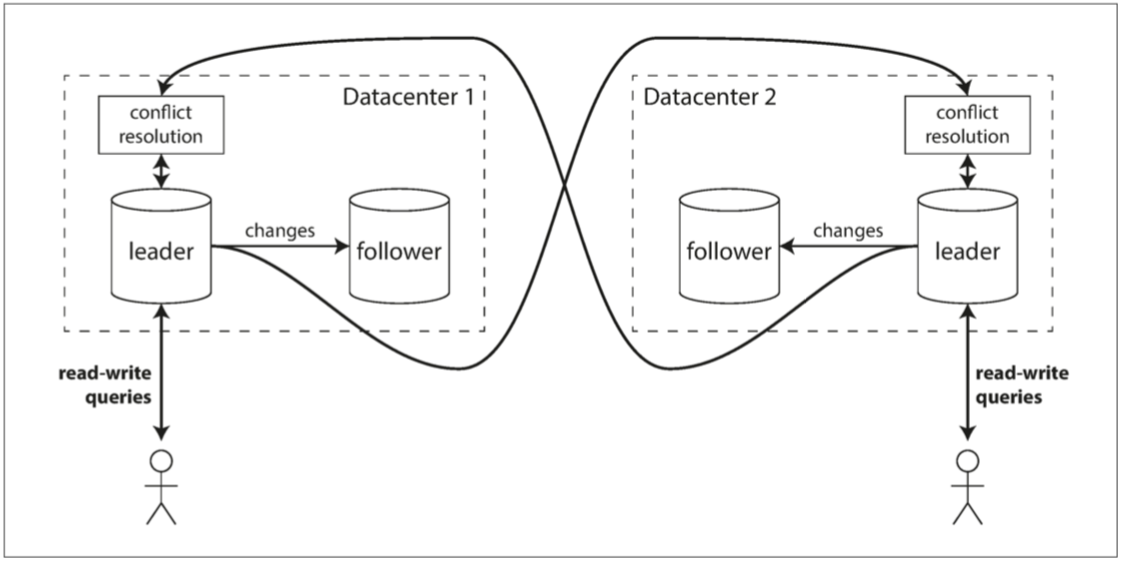
- 圖 5-6 跨多個數據中心的多主複製
我們來比較一下在運維多個數據中心時,單領導和多領導的適應情況
- 效能
- 單領導:寫入需穿越網際網路,增加寫入時間。
- 多領導:寫入在本地資料中心進行,降低網路延遲影響。
- 容忍資料中心停機
- 單領導:需故障切換,從庫成為主庫。
- 多領導:各資料中心獨立運作,故障資料中心恢復後自動複製。
- 容忍網路問題
- 單領導:對資料中心間連線問題敏感,寫入為同步操作。
- 多領導:採非同步複製,對網路問題有更高的承受能力。
一些資料庫支援多領導配置,並且可以透過外部工具實現。 儘管多領導複製具有優點,但也存在寫衝突問題。
此外,由於多領導複製在很多資料庫中是改裝功能,可能會有一些配置上的缺陷,並可能與其他資料庫功能產生意外反應。 因此,多領導複製被認為是一個高風險領域,應該盡量避免使用。
客戶端的離線操作
另一種適用多領導複製的場景,即需要在斷網狀態下仍能使用的應用程式 例如日曆應用程式。 在這種情況下,每個裝置都有一個本地資料庫,並存在非同步的多主複製過程來同步日曆副本。 這種設定類似於資料中心之間的多領導複製,但網路連線極不可靠。
雖然有一些工具可以幫助實現多領導複製,但實際應用中仍然有很多難點需要克服。
其中一個工具是CouchDB。
協作編輯
這種應用允許多人同時編輯同一份文件,例如 Etherpad 和 Google Docs。
為了避免編輯衝突,應用程式必須先取得文件的鎖定,然後才能進行編輯。 但為了加速協作,可能會將更改的單位設定得非常小,並避免鎖定。
這種方法允許多個使用者同時進行編輯,但需要解決衝突。 這種協作模式相當於主從複製模型下在主節點上執行事務操作。
處理寫入衝突
容易遇到寫衝突的問題。 例如,兩個使用者同時編輯同一個維基頁面,且對同一個標題進行修改,這就可能發生衝突。
這時需要解決衝突,以保證數據的一致性。 多領導者的資料庫同步上 通常被認為有風險,應儘量避免.
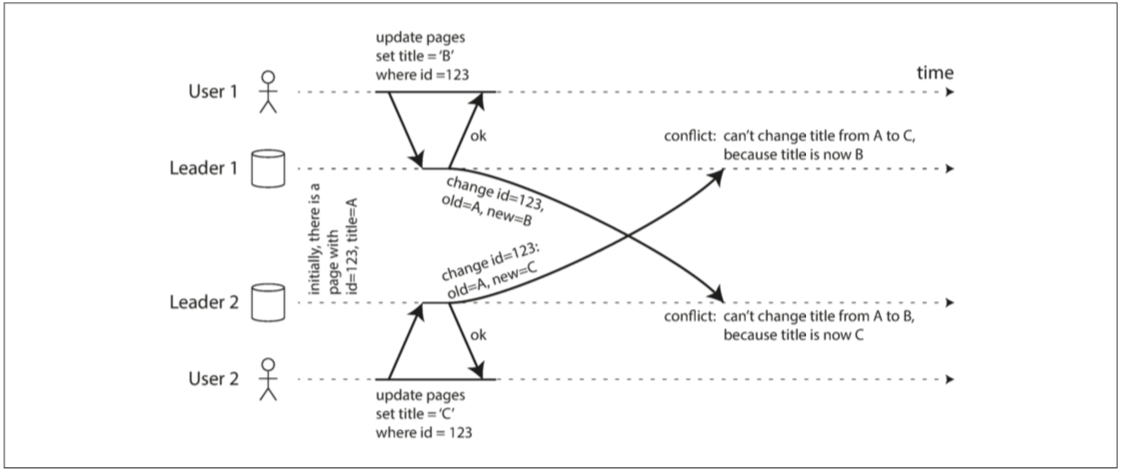
- 圖 5-7 兩個主節點同時更新同一記錄引起的寫入衝突
同步與非同步衝突檢測
在單領導資料庫中,兩個寫入操作會發生阻塞,必須等待第一個操作完成才能進行第二個。
而在多領導配置中,兩個操作都能成功進行,但是衝突的檢測需要在稍後的時間進行,可能導致解決衝突的過程較為困難。
如果想要同步衝突檢測,可以等待所有副本接受寫入後再告訴使用者寫入成功,但是這樣會失去多領導複製的優勢。 如果需要同步衝突檢測,建議使用單領導複製。
避免衝突
最簡單策略,即確保所有寫入特定記錄的操作都透過同一個主庫進行。 這樣可以避免多個主庫同時寫入同一個記錄而導致衝突。
然而,如果需要更改指定的主庫,例如因為某個資料中心出現故障,就需要處理不同主庫同時寫入的可能性。 這需要在應用程式中實現一些特殊處理。
漸趨一致的狀態
如何處理多個複本之間的數據一致性問題。 當單個主資料庫進行寫操作時,最後一次寫操作將決定該欄位的最終值。
但在多主配置中,由於沒有明確的寫入順序,最終值很難確定。 因此,必須以一種收斂的方式解決衝突,以確保所有複本的最終值都是相同的。
有多種方法可以實現這個目標,其中包括:
- 使用唯一 ID 來選擇勝利者並丟棄其他寫入,這種方法稱為最後寫入勝利。然而,這種方法容易造成資料丟失。
- 為每個副本分配一個唯一的 ID,以 ID 編號較高的寫入為優先。同樣,這種方法也可能導致資料丟失。
- 將寫入的值合併在一起,例如按字母順序排序後合併。
- 使用顯式資料結構記錄衝突,然後編寫解決衝突的程式碼來保留所有資訊。
自訂解決衝突的邏輯
- 寫入時執行 指當資料庫系統在複製更改日誌中發現衝突時,會立即呼叫衝突處理程式碼。
- 讀取時執行 將所有的不同版本都儲存在資料庫中。 當應用程式下一次讀取這些資料時,會將這些不同版本的資料都返回給應用程式。 應用程式可以讓使用者解決衝突或自動解決衝突,然後將結果寫回資料庫。 這是一種常見的解決衝突的方法,例如 CouchDB 就是這樣做的。
自動衝突解決 衝突解決規則可能很容易變得越來越複雜,自定義程式碼可能也很容易出錯。 亞馬遜是一個經常被引用的例子,由於衝突解決處理程式而產生了令人意外的效果:一段時間以來,購物車上的衝突解決邏輯將保留新增到購物車的物品,但不包括從購物車中移除的物品。 因此,顧客有時會看到物品重新出現在他們的購物車中,即使他們之前已經被移走【37】。
已經有一些有趣的研究來自動解決由於資料修改引起的衝突。有幾項研究值得一提:
- 無衝突複製資料型別(Conflict-free replicated datatypes,CRDT)【32,38】是可以由多個使用者同時編輯的集合、對映、有序列表、計數器等一系列資料結構,它們以合理的方式自動解決衝突。一些 CRDT 已經在 Riak 2.0 中實現【39,40】。
- 可合併的持久資料結構(Mergeable persistent data structures)【41】顯式跟蹤歷史記錄,類似於 Git 版本控制系統,並使用三向合併功能(而 CRDT 使用雙向合併)。
- 操作轉換(operational transformation)42 是 Etherpad 【30】和 Google Docs 【31】等協同編輯應用背後的衝突解決演算法。它是專為有序列表的並發編輯而設計的,例如構成文字文件的字元列表。 這些演算法在資料庫中的實現還很年輕,但很可能將來它們會被整合到更多的複製資料系統中。自動衝突解決方案可以使應用程式處理多主資料同步更為簡單。
怎樣才算衝突?
有些衝突是明顯的,例如同時修改同一欄位的寫操作,但有些衝突可能不太容易察覺,
例如在會議室預訂系統中避免同一房間的重疊預訂,雖然可以在預訂時再次檢查,但在多領導不同主庫時還是可能發生衝突.
接下來的章節將進一步討論如何解決這些衝突, 包括在第七章中介紹更多衝突案例,以及在第十二章中討論檢測和解決衝突的可伸縮方法。
Multi-Leader 複製的拓樸
即資料如何從一個節點傳播到另一個節點。 當有兩個主庫時,唯一合理的拓撲是將所有寫入都發送到對方。
但如果有兩個以上的主庫時,就有多種不同的拓撲結構可選擇。
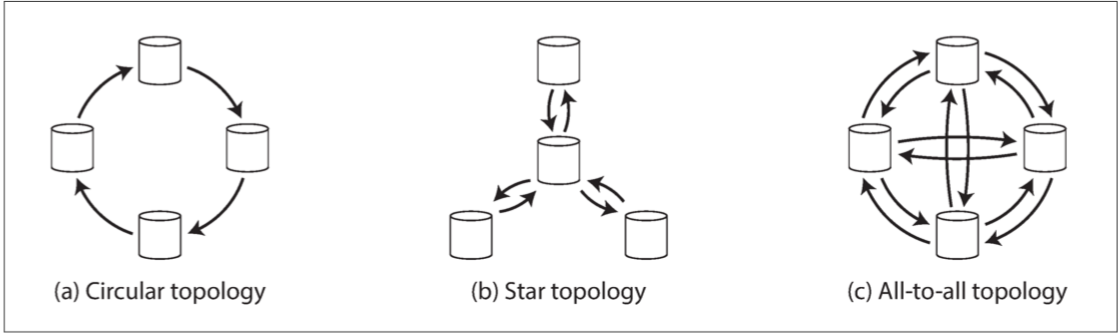
- 圖 5-8 三種可以在多主複製中使用的拓撲示例。
常見的三種拓撲結構
- 環狀拓墣
- 星狀拓墣
- All to all 拓墣
其中,全部到全部的拓撲結構容錯性較好,因為它可以避免單點故障,但可能存在訊息超前的問題。 而環形和星形拓撲結構的容錯性較差,一旦某個節點出現故障,可能會中斷複製訊息流,需要手動重新配置。
此外,在環形和星形拓撲中,為了避免無限複製迴圈,每個節點都被賦予一個唯一的識別符號。
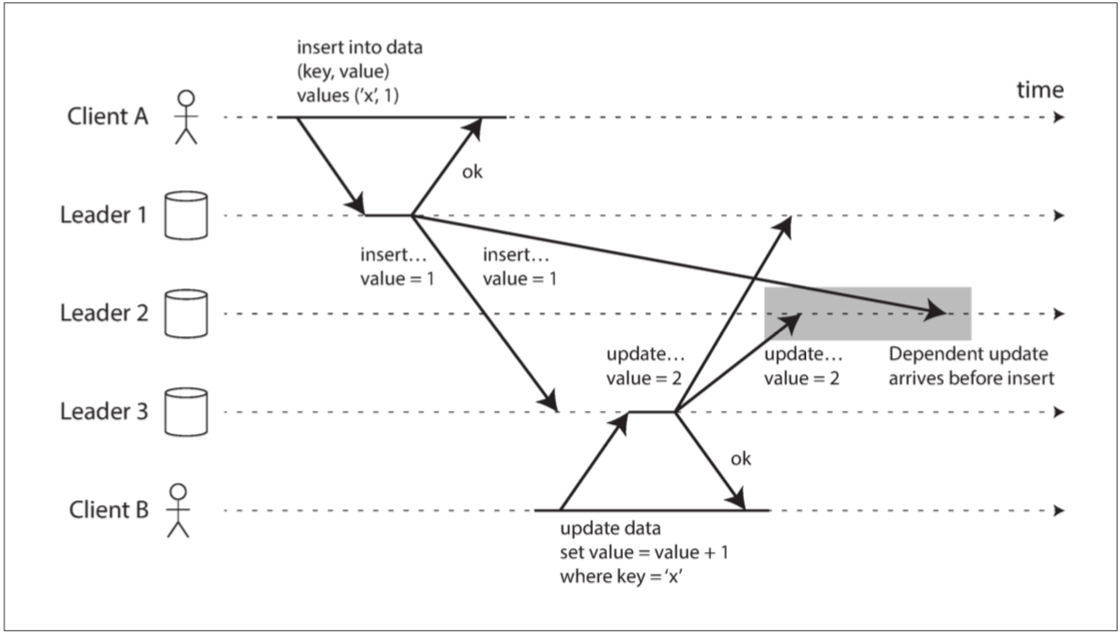
- 圖 5-9 使用多主複製時,寫入可能會以錯誤的順序到達某些副本。
多主複製系統中的一個因果關係問題,
例如當不同的節點以不同順序處理寫入時可能會發生衝突。 為了解決這個問題,可以使用**版本向量(version vectors)**技術進行排序。
但是,有些多主複製系統的衝突檢測技術可能不夠好,因此在使用這些系統時應該仔細閱讀文件並進行測試,以確保系統能提供所需的保證。
無領導複製
本章節討論了不同的複製方法,如單主複製和多主複製,它們的共同點是都有一個主庫來處理寫請求。
然而,無主複製方法不同,因為它不依賴主庫。
無主複製系統如 Dynamo、Riak、Cassandra 和 Voldemort 允許客戶端直接向副本寫入資料,或通過協調者節點進行寫入。 無主複製設計對資料庫的使用方式具有重要影響。
當節點失效時寫入資料庫
假設有三個副本的資料庫。當其中一個副本不可用時,基於領導者的配置可能需要進行故障切換。
然而,在無主配置中,故障轉移不存在。 客戶端會將寫入傳送到所有副本,而無需擔心其中一個副本錯過了寫入。
只要有兩個副本確認寫入,就認為寫入成功。
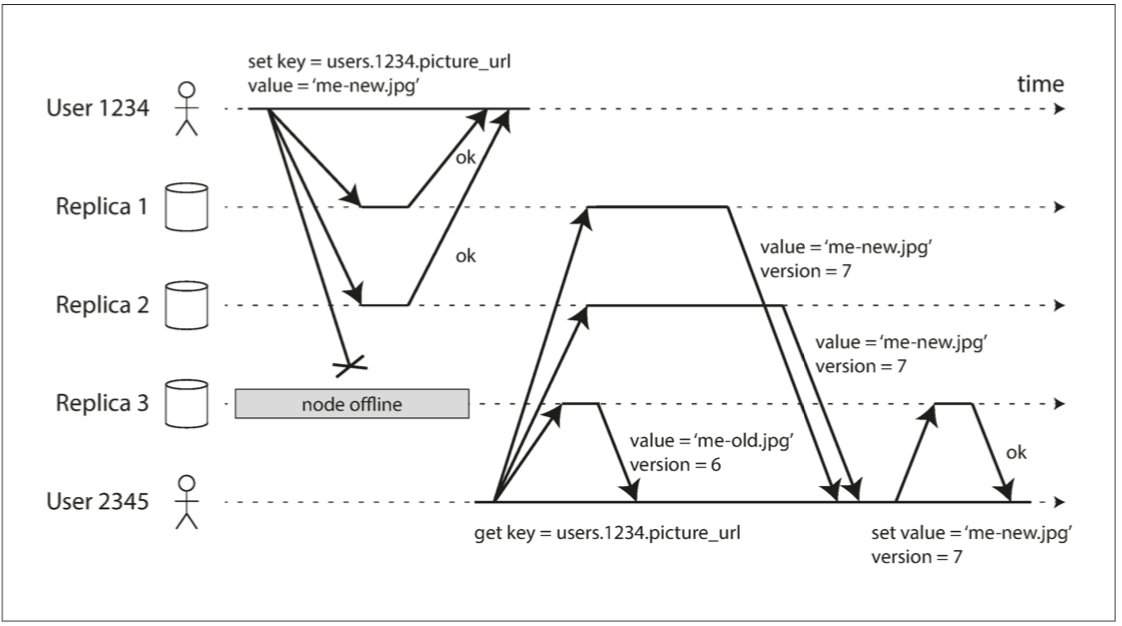
圖 5-10 法定寫入,法定讀取,並在節點中斷後讀修復。
作者提到了節點重新連線後的數據同步問題。
為了解決可能讀取到過時數據的問題,客戶端會向多個節點發送讀請求。 然後,通過版本號確定各節點返回的數據哪個是最新的,以避免使用到舊的數據資料。
利用讀取來修復和反熵
在密集型應用的資料複製過程中,有兩種常用的方法來確保所有資料在各個副本中一致:
- 利用讀取來修復:客戶端在讀取多個節點時,檢測並修正舊的數據資料(傳送新值給該節點),適用於經常被讀取的值。
- 反熵過程:一個後台程序在副本間不斷檢查並複製缺失的資料,不依賴特定的順序,可能有一定延遲。
然而,並非所有系統都實現了這兩種機制。如果沒有反熵過程,很少被讀取的值可能會丟失,降低了永續性。
讀取和寫入的法定票數演算(Quorums)
我們討論了資料密集型應用中的資料副本。
以三個副本的情況為例,只要至少有兩個副本完成寫入,該寫入就算成功。為了確保讀取到的資料是最新的,我們需要從至少兩個副本讀取。 通常,n 代表副本數,w 代表寫入成功需要的節點數,r 代表讀取需要查詢的節點數。
只要 r 和 w 的和大於 n,就能確保讀取到最新的資料。 這種讀寫方法被稱為法定人數的讀寫。
在 Dynamo 風格的資料庫中,n、w 和 r 的值都是可配置的,可以根據需求進行調整。
叢集中可能有多於 n 個的節點(叢集的機器數可能多於副本數目)。但是任何給定的值只能儲存在 n 個節點上。這允許對資料集進行分割槽,從而可以支援比單個節點的儲存能力更大的資料集。我們將在 第六章 繼續討論分割槽。
- 如果 w < n ,當節點不可用時,我們仍然可以處理寫入。
- 如果 r < n ,當節點不可用時,我們仍然可以處理讀取。
- 對於 n = 3,w = 2,r = 2,我們可以容忍一個不可用的節點。
- 對於 n = 5,w = 3,r = 3,我們可以容忍兩個不可用的節點。 這個案例如 圖 5-11 所示。
- 通常,讀取和寫入操作始終並行傳送到所有 n 個副本。引數 w 和 r 決定我們等待多少個節點,即在我們認為讀或寫成功之前,有多少個節點需要報告成功。
圖 5-11 如果 w + r > n ,讀取 r 個副本,至少有一個副本必然包含了最近的成功寫入。
在進行資料寫入或讀取時,如果可用節點少於所需的 w 或 r 值,將會出現錯誤。 節點失效可能有多種原因,如節點關閉、操作錯誤或網路問題等。
我們只需關注節點是否成功響應,而無需區分錯誤類型。
Quorum 一致性的限制
當有 n 個副本,並滿足 w + r > n 的條件時,通常每次讀取都能獲得最新寫入的值。 為確保 w + r > n,並在節點故障時保持可靠性,r 和 w 通常被選為大於 n/2 的數字。 設計分散式算法時,可以靈活選擇其他讀寫節點數量。
當 w 和 r 設定較小,以使 w + r <= n 時,讀取和寫入操作僅需要少量成功響應。 這樣的設定可以提高可用性和降低延遲,但可能導致讀取到較舊的資料。 只有當可達副本數量低於 w 或 r 時,資料庫才無法進行讀寫。
雖然法定人數 (w + r > n) 似乎可以保證讀取返回最新的寫入值,但實際上仍可能出現邊緣情況,導致讀取到舊的 數據資料。 這些邊緣情況包括寫入和讀取落在不同節點上、寫入衝突、寫入和讀取同時進行、寫入部分成功或節點故障等。
因此,在實踐中,Dynamo 風格的資料庫通常對可容忍最終一致性的用例進行最佳化。 雖然可以通過調整 w 和 r 的值來減少讀取到陳舊值的機率,但將其視為絕對保證是不明智的。
為了獲得更強有力的保證,可能需要使用交易(Translation)或共識方法(Consensus Algorithm)。
監控舊值
在監控資料庫健康狀況時,了解複製延遲和陳舊讀取對於確保數據準確性非常重要。
對於基於領導者的複製,可以通過比較主從庫的位置來測量延遲解決舊數據資料的判斷。
但是無主複製系統的監控更為困難,無主寫入順序是不固定的,讓監控更加困難. 如果沒有反熵,落後程度就會沒有上限.
目前對於無主複製的監測有一定的研究,但尚未普及。
將陳舊測量值納入標準度量集是有益的, 因為最終一致性是個模糊的保證,從維運角度來看,最終"量化"仍然是件很重要的事情。
寬鬆的Quorums和提示移交
使用合理配置的法定人數可以讓資料庫在不需要故障切換的情況下容忍節點故障。 這對於需要高可用性、低延遲並能容忍偶爾讀取到舊資料的應用非常有吸引力。
然而,法定人數在網路中斷時可能無法如預期那樣具有容錯性。
如果客戶端與資料庫節點失去連接,則剩餘的可用節點可能不足以達到法定人數,導致客戶端無法正常使用資料庫。 如果在網路中斷期間客戶端能連線到部分資料庫節點,但無法達到法定節點數量,設計人員需考慮:
- 對無法滿足法定 w 或 r 個節點數的請求是否返回錯誤?
- 或是接受寫入,寫到部分可達節點,而非常見制定的 n 個節點?「寬鬆的Quorums」
簡而言之,如何在網路中斷時保證資料庫正常運行是設計人員需要考慮的問題。 寬鬆的法定人數(sloppy quorum)在設計資料密集型應用的過程中的作用。
當網路出現問題時,寬鬆的法定人數可以提高寫入可用性,允許寫入操作在任何可用的節點上完成。 但這種方法不能確保讀取到最新的數據,因為最新的數據可能已經暫時寫入了不在主節點集合中的節點。
提示移交(hinted handoff)機制可在網路問題解決後將這些暫時寫入的數據傳送到主節點。
寬鬆的Quorums 模式 在不同的 Dynamo 實現中是可選的,並且其預設設置因實現而異。
多資料中心營運
無領導複製在多資料中心操作中的適用性,特別是在容忍衝突、網路中斷和延遲尖峰方面。Cassandra 和 Voldemort 運用無主模型來實現多資料中心支援,
將副本分布在各個資料中心,並允許配置每個資料中心的副本數量。
客戶端通常僅等待本地資料中心內的法定節點確認,以減少跨資料中心鏈路延遲和中斷的影響。
Riak 則將通訊限制在單一資料中心範圍內,並在後台非同步執行跨資料中心的複製。
檢測並發寫入
Dynamo 風格的資料庫可能會遇到衝突問題,因為多個客戶端可以同時寫入相同的鍵。
由於網路延遲和部分節點故障,事件可能以不同順序到達不同節點,導致衝突。
例如,圖 5-12 顯示了兩個客戶機 A 和 B 同時寫入三節點資料儲存中的鍵 X:
- 節點 1 接收來自 A 的寫入,但由於暫時中斷,未接收到來自 B 的寫入。
- 節點 2 首先接收來自 A 的寫入,然後接收來自 B 的寫入。
- 節點 3 首先接收來自 B 的寫入,然後從 A 寫入。
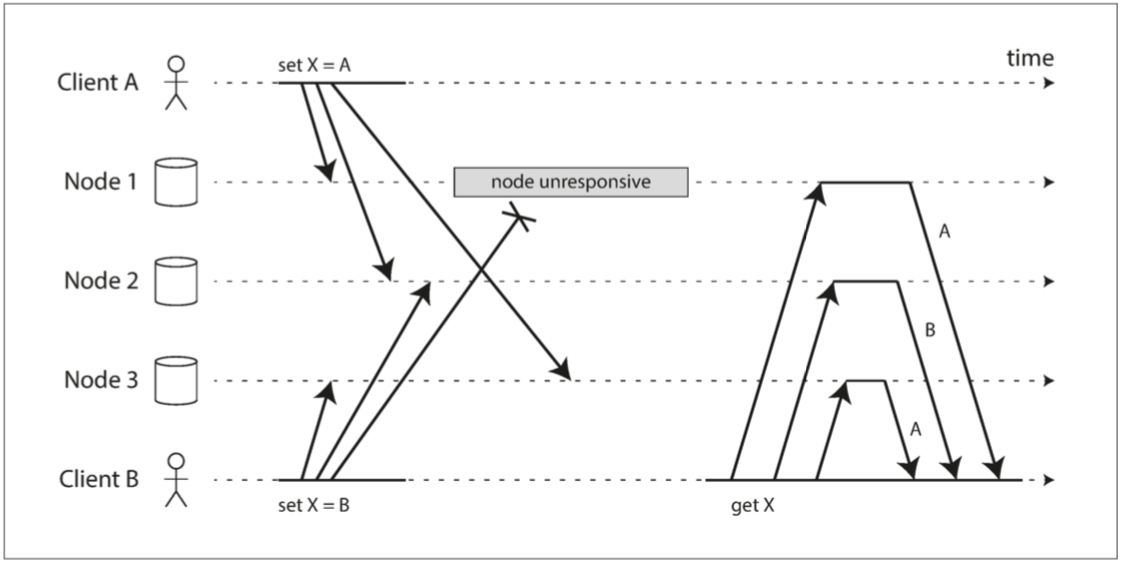
圖 5-12 並發寫入 Dynamo 風格的資料儲存:沒有明確定義的順序。
如何達成一致性。為了達成一致性,副本應該趨於相同的值。
雖然理想情況下,資料庫應該自動處理複製衝突,但實際上可能需要應用程式開發人員具備一定的資料庫內部知識來避免資料丟失。
本章還將更深入地探討解決衝突的方法。
後寫者贏(丟棄並發的寫入)
為了實現最終收斂,可以使用最後寫入勝利LWW(Last Write Win)方法,即選擇具有最大時間戳的寫入作為最新的,並丟棄具有較早時間戳的寫入。
但是,LWW會以永續性為代價,可能導致部分寫入丟失。 在某些情況下,例如快取,這可能是可以接受的,但如果資料丟失不可接受,則LWW可能不是最佳選擇。
要安全地在資料庫中使用LWW,應確保每個鍵只寫入一次,並將其視為不可變,以避免對同一個鍵進行並發更新。
happens-before 和並發性
判斷兩個操作是否並發的關鍵在於一個操作是否在另一個操作之前發生。 當兩個操作互不知道對方時,它們是並發的。
在這種情況下,需要解決潛在的衝突。總結來說,操作的並發性可以分為三種情況:
- A 在 B 之前
- B 在 A 之前
- A 和 B 並發
並發性、時間和相對性 如果兩個操作 “同時” 發生,似乎應該稱為並發 —— 但事實上,它們在字面時間上重疊與否並不重要。由於分散式系統中的時鐘問題,現實中是很難判斷兩個事件是否是 同時 發生的,這個問題我們將在 第八章 中詳細討論。
為了定義並發性,確切的時間並不重要:如果兩個操作都意識不到對方的存在,就稱這兩個操作 並發,而不管它們實際發生的物理時間。人們有時把這個原理和物理學中的狹義相對論聯絡起來【54】,該理論引入了資訊不能> 比光速更快的思想。因此,如果兩個事件發生的時間差小於光透過它們之間的距離所需要的時間,那麼這兩個事件不可能相互影響。
在計算機系統中,即使光速原則上允許一個操作影響另一個操作,但兩個操作也可能是 並發的。例如,如果網路緩慢或中斷,兩個操作間可能會出現一段時間間隔,但仍然是並發的,因為網路問題阻止一個操作意識到另一個操作的存在。
擷取 happens-before 先後關係
用於確定兩個操作是否為並發的,或者一個在另一個之前。 該例子中,兩個客戶端同時將商品加入購物車。
這個過程涉及五次寫入操作,每次客戶端嘗試將新商品添加到購物車時,伺服器都會分配新的版本號。 在這個過程中,不同客戶端的操作可能互相影響,最後伺服器將保留並發值。
簡單來說,該演算法是為了確定操作之間的並發性,並根據操作的順序和版本號來合併購物車內容。
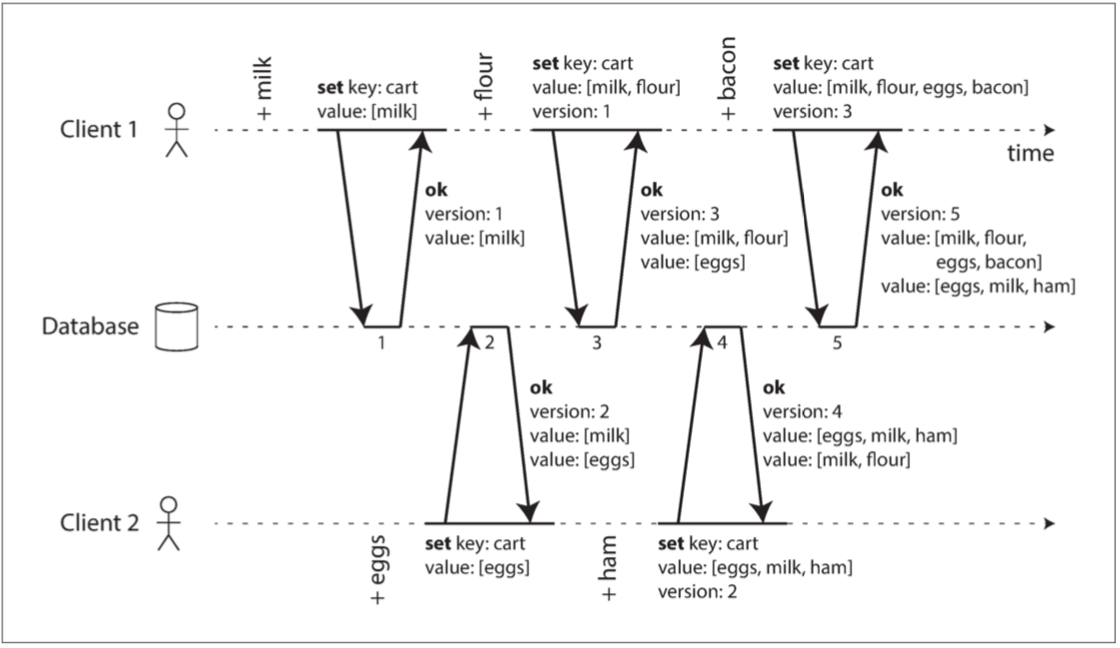
圖 5-13 在同時編輯購物車時捕獲兩個客戶端之間的因果關係。
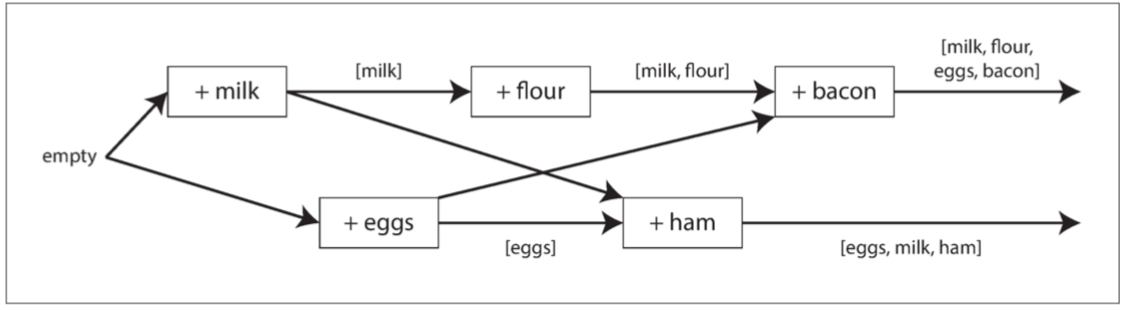
圖 5-14 圖 5-13 中的因果依賴關係圖。
該演算法的工作原理如下
- 伺服器為每個鍵維護一個版本號,寫入時遞增版本號,並將新版本號與值一起儲存。
- 客戶端讀取鍵時,伺服器返回所有未覆蓋值及最新版本號;客戶端需先讀取再寫入。
- 客戶端寫入鍵時,附帶讀取的版本號,並將之前讀取的所有值合併在一起。
- 伺服器收到寫入時,覆蓋相同或更低版本號的值,並以更高版本號儲存所有值。
寫入時包含讀取的版本號有助於確定寫入基於的狀態。 無版本號的寫入與其他寫入並發,不會覆蓋內容,而只會作為隨後讀取的一個值返回。
合併並發寫入的值
當多個客戶端同時進行資料寫入時,如何解決衝突並合併資料。
以購物車為例,作者提出一種將並發值做並集的合併方法。 然而,若要允許用戶移除購物車中的項目,這種方法可能無法產生正確結果。
為解決這個問題,系統應留下刪除標記(墓碑),以表示某個項目已被移除。 另外,為簡化合併過程,有一些資料結構(如CRDT)可自動執行合併操作。
版本向量
在圖 5-13 的例子中,僅使用了一個副本。
當有多個副本而無主庫時,我們需要修改算法。 我們將使用版本向量來捕捉多個副本之間的依賴關係,每個副本都有自己的版本號。
當副本處理寫入時,版本號會增加,並追踪其他副本的版本號。 這有助於確定覆蓋哪些值以及保留哪些值。
版本向量允許區分覆蓋寫入和並發寫入,並確保從一個副本讀取並寫回到另一個副本是安全的。 然而,應用程式可能需要合併並發值。 只要能正確合併,就不會丟失資料。
版本向量和向量時鐘 版本向量有時也被稱為向量時鐘,即使它們不完全相同。其中的差別很微妙 —— 細節請參閱參考資料【57,60,61】。簡而言之,在比較副本的狀態時,版本向量才是正確的資料結構。
小結
在本章中,我們考察了複製的問題。複製可以用於幾個目的:
- 高可用性
即使在一臺機器(或多臺機器,或整個資料中心)停機的情況下也能保持系統正常執行 - 斷開連線的操作
允許應用程式在網路中斷時繼續工作 - 延遲
將資料放置在地理上距離使用者較近的地方,以便使用者能夠更快地與其互動 - 可伸縮性
透過在副本上讀,能夠處理比單機更大的讀取量
儘管是一個簡單的目標 - 在幾臺機器上保留相同資料的副本,但複製卻是一個非常棘手的問題。它需要仔細考慮並 發和所有可能出錯的事情,並處理這些故障的後果。至少,我們需要處理不可用的節點和網路中斷(這還不包括更隱蔽的故障,例如由於軟體錯誤導致的靜默資料損壞)。
我們討論了複製的三種主要方法:
- 單主複製
客戶端將所有寫入操作傳送到單個節點(主庫),該節點將資料更改事件流傳送到其他副本(從庫)。讀取可以在任何副本上執行,但從庫的讀取結果可能是陳舊的。 - 多主複製
客戶端將每個寫入傳送到幾個主庫節點之一,其中任何一個主庫都可以接受寫入。主庫將資料更改事件流傳送給彼此以及任何從庫節點。 - 無主複製
客戶端將每個寫入傳送到幾個節點,並從多個節點並行讀取,以檢測和糾正具有陳舊資料的節點。
每種方法都有優點和缺點。單主複製是非常流行的,因為它很容易理解,不需要擔心衝突解決。在出現故障節點、網路中斷和延遲峰值的情況下,多主複製和無主複製可以更加健壯,其代價是難以推理並且僅提供非常弱的一致性保證。
複製可以是同步的,也可以是非同步的,這在發生故障時對系統行為有深遠的影響。儘管在系統執行平穩時非同步複製速度很快,但是要弄清楚在複製延遲增加和伺服器故障時會發生什麼,這一點很重要。如果主庫失敗後你將一個非同步更新的從庫提升為新的主庫,那麼最近提交的資料可能會丟失。
我們研究了一些可能由複製延遲引起的奇怪效應,我們也討論了一些有助於決定應用程式在複製延遲時的行為的一致性模型:
- 寫後讀一致性
使用者應該總是能看到自己提交的資料。 - 單調讀
使用者在看到某個時間點的資料後,他們不應該再看到該資料在更早時間點的情況。 - 一致字首讀
使用者應該看到資料處於一種具有因果意義的狀態:例如,按正確的順序看到一個問題和對應的回答。
最後,我們討論了多主複製和無主複製方法所固有的並發問題:因為他們允許多個寫入並發發生,這可能會導致衝突。我們研究了一個數據庫可以使用的演算法來確定一個操作是否發生在另一個操作之前,或者它們是否並發發生。我們還談到了透過合併並發更新來解決衝突的方法。
在下一章中,我們將繼續考察資料分佈在多臺機器間的另一種不同於 複製 的形式:將大資料集分割成 分割槽。