設計資料密集型應用-ch9
一致性與共識
目錄
9.1 一致性保證
大多數複製的資料庫至少提供了最終一致性,這意味著如果你停止向資料庫寫入資料並等待一段不確定的時間,那麼最終所有的讀取請求都會返回相同的值。換句話說,不一致性是暫時的,最終會自行解決(假設網路中的任何故障最終都會被修復。
對於應用開發人員而言,最終一致性是很困難的,因為它與普通單執行緒程式中變數的行為有很大區別。如果將一個值賦給一個變數,然後很快地再次讀取,不可能讀到舊的值,或者讀取失敗。資料庫表面上看起來像一個你可以讀寫的變數,但實際上它有更複雜的語義。
我們在使用弱一致性的資料庫時必須了解弱一致性的局限性,因為錯誤常常很難找到也很難測試,因為應用可能在大多數情況下執行良好。當系統出現故障(例如網路中斷)或高併發時,最終一致性的邊緣情況才會顯現出來。
| 強一致性 | 弱一致性 | |
|---|---|---|
| 解釋 | 強一至性表示,一旦一個操作(如寫入)完成,該操作的效果會立即反映在接下來所有的讀取操作上,無論這些讀取操作是從哪個節點發出的。 | 在弱一至性模型下,寫入操作的效果可能不會立即反映在隨後的讀取操作中,特別是來自其他節點的讀取操作。 |
| 例子 | 假設你在銀行轉帳,當錢從一個帳戶轉到另一個帳戶後,不管是你自己還是其他任何人,只要查詢餘額,都會立即看到最新的數字。 | 假設你更新了你的社交媒體狀態。你的朋友可能會在幾秒鐘後或幾分鐘後才看到這個更新,取決於各種因素(如網絡延遲、緩存等)。 |
| 模型 | 線性一致性(linearizability)最強 | 最終一致性(Eventual Consistency) |
| 容錯性 | 少 | 高 |
| 所需資源 | 高 | 低 |
| 實踐 | 易 | 難 |
9.2 線性一致性
介紹:
在最終一致的資料庫,如果你在同一時刻問兩個不同副本相同的問題,可能會得到兩個不同的答案。這很讓人困惑。如果資料庫可以提供只有一個副本的假象(即,只有一個數據副本),那麼事情就簡單太多了。每個客戶端都會有相同的資料檢視,且不必擔心複製滯後了。
這種抽象的想法也稱為原子一致性(atomic consistency)【7】,強一致性(strong consistency),立即一致性(immediate consistency) 或 外部一致性(external consistency )
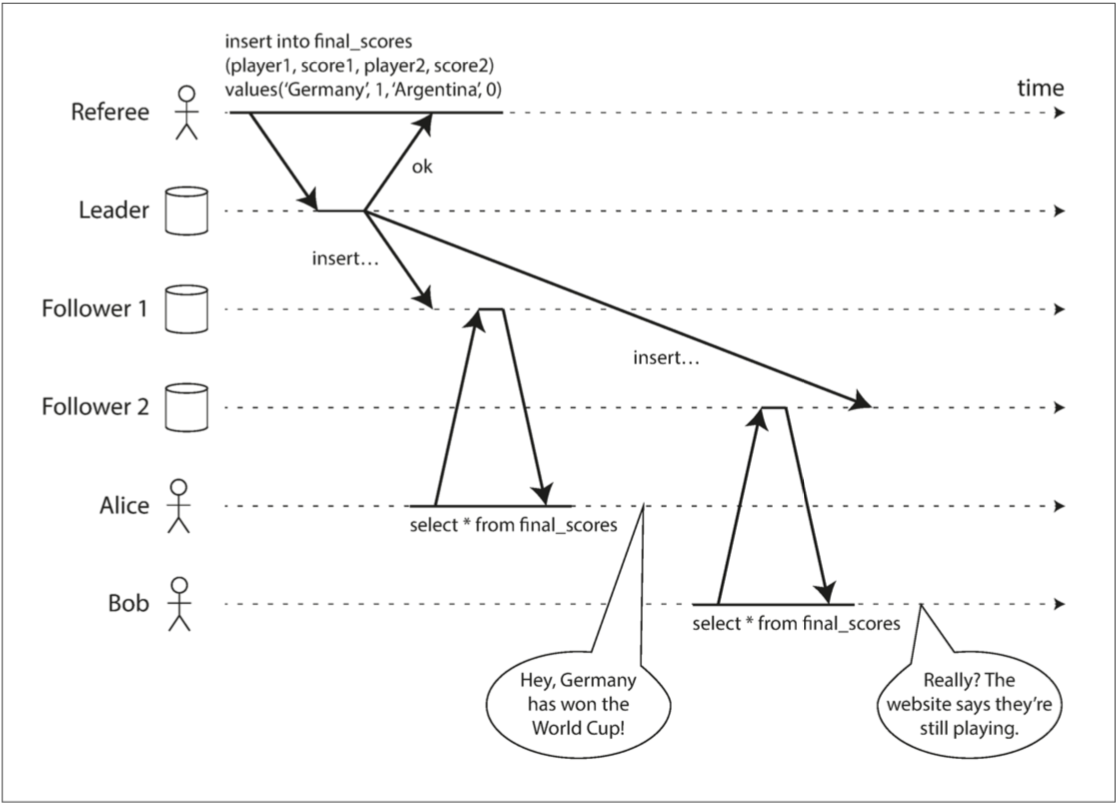
圖 9-1 這個系統是非線性一致的,導致了球迷的困惑
描述:
計分員成功寫入德國獲勝到Leader
Leader開始寫入Foll1 Foll2
Alice用手機看到德國贏了然後Bob因為Leader寫入的時間差以為比賽還在進行
是什麼東西可以讓系統線性一致**?**
介紹:
真正的想法就是如何讓操作多個資料庫像在單一操作一個資料庫一樣
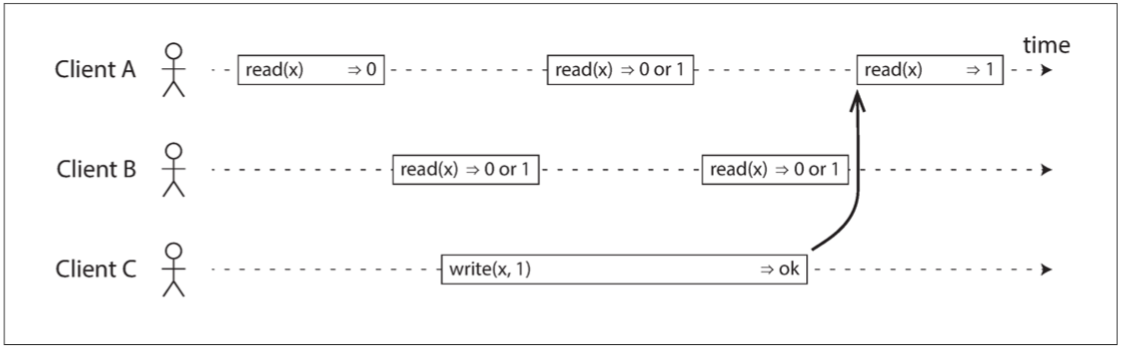
圖 9-2 如果讀取請求與寫入請求併發,則可能會返回舊值或新值
x稱為暫存器,可以是鍵或是資料庫的行或是資料庫的一個文件
描述:
A與B會在C寫入中產生不確定性
test
package main
import (
"log"
"math/rand"
"sync"
"time"
)
type DB struct {
Value int
}
type Client struct {
Name string
wg *sync.WaitGroup
}
func (c *Client) Read(db *DB) {
defer c.wg.Done()
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(10)))
log.Printf("%s x=%d %v \n", c.Name, db.Value, time.Now().UnixMilli())
}
}
func (c *Client) Write(db *DB, i int) {
defer c.wg.Done()
time.Sleep(time.Millisecond * time.Duration(rand.Intn(10)))
db.Value = i
}
func main() {
rand.Seed(time.Now().UnixNano())
wg := &sync.WaitGroup{}
wg.Add(3)
db := &DB{Value: 0}
clientA := &Client{Name: "ClientA", wg: wg}
clientB := &Client{Name: "ClientB", wg: wg}
clientC := &Client{Name: "ClientC", wg: wg}
go clientA.Read(db)
go clientB.Read(db)
go clientC.Write(db, 1)
wg.Wait()
}
/*
2023/09/01 17:34:13 ClientA x=0 1693560853277
2023/09/01 17:34:13 ClientA x=0 1693560853278
2023/09/01 17:34:13 ClientB x=0 1693560853278
2023/09/01 17:34:13 ClientA x=0 1693560853283
2023/09/01 17:34:13 ClientB x=1 1693560853288
2023/09/01 17:34:13 ClientB x=1 1693560853298
*/
為了使系統線性一致需要新增另外一個約束“只要有任何一個Client讀取x都必須返回最新值
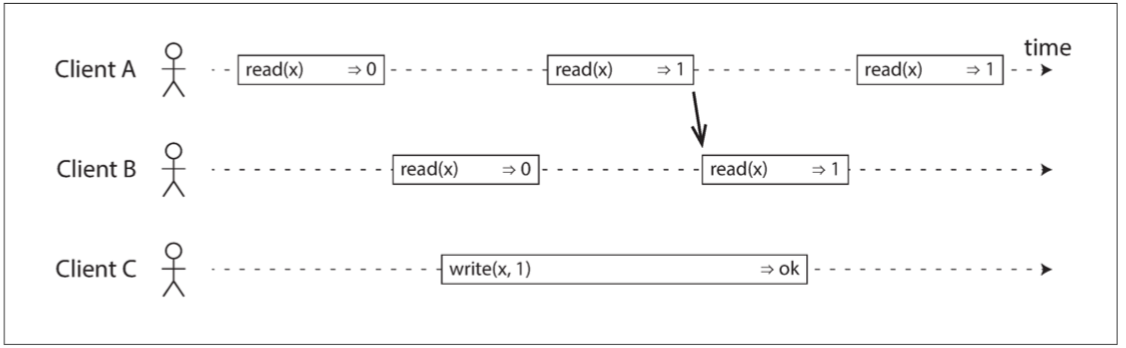
圖 9-3 任何一個讀取返回新值後,所有後續讀取(在相同或其他客戶端上)也必須返回新值。
描述:
這張圖是與上一個圖的比較,這張圖是最後想要達到的目標(線性一致)也就是我不管C到底在哪個時間點真正寫入,只要A已經讀到1的話,B永遠不能讀到其他值一定要是1
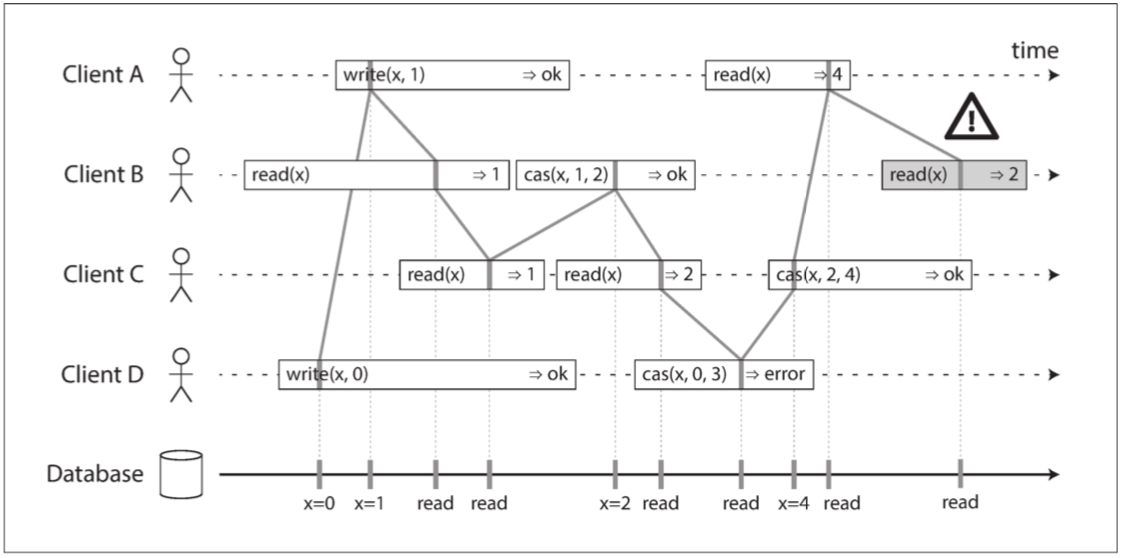
圖 9-4 視覺化讀取和寫入看起來已經生效的時間點。 B 的最後讀取不是線性一致性的
描述:
這邊想要描述如果write與cas混用會發生什麼問題
D最後出錯了原因是他一開始沒有用cas先比較資料庫原本有的內容是什麼等到他想用cas的時候發現cas(2,0,3) 2≠0 所以error,
C想用cas更新資料庫,而C最後一次的記憶體裡面x=2所以cas(2,2,4) 2=2所以x更新成4
第七章CAS(Compare and Swap)的解釋 *補全
第7章”事務”有提到CAS與ACID
cas(實例數值(內存數值),期望數值,更新數值) = True or False
sequenceDiagram
participant T1
participant Memory
participant T2
Note over Memory: x=77
T2->>Memory: 讀取數值 (Read x)
Memory->>T2: 返回 77
T1->>Memory: 讀取數值 (Read x)
Memory->>T1: 返回 77
Note over T1,T2: 開始競爭搶做cas更新
Note over T1,Memory: T1先搶到開始做cas
T1->>Memory: CAS(77, 77, 78)
Note over Memory: 比較 77 == 77
Memory->>T1: CAS成功,更新為78
Note over Memory: x=78
Note over Memory,T2: T2比T1晚一步做cas
T2->>Memory: CAS(78, 77, 7788)
Note over Memory: 比較 78 != 77
Memory->>T2: CAS失敗
Note over Memory: 最終數值為 x=78
*重點:
CAS只在乎寫,而初始值的讀取可以是刻意先去讀或者是曾經讀過
沒有先讀的cas不能比較
test
type CAS struct {
value int
}
func (c *CAS) CompareAndSwap(expected int, newValue int) bool {
if c.value == expected {
c.value = newValue
return true
}
return false
}
第7章說CAS是輕型事務所以用redis了解了一下事務
最後對於cas的理解就像是redis的watch會去監視某個key當某個key被併發寫入時就會發出錯誤停止事務
go func(){ //A
WATCH x
MULTI
SET x "newValueFromA"
EXEC
}()
go func(){ //B
WATCH x
MULTI
SET x "newValueFromB"
EXEC
}()
/*
2023/09/04 00:06:19 Goroutine A aborted: redis: transaction failed
2023/09/04 00:06:19 Goroutine B succeeded
2023/09/04 00:06:19 Final value of x: newValueFromB
*/
test
package main
import (
"context"
"log"
"sync"
"github.com/go-redis/redis/v8"
)
func main() {
var ctx = context.Background()
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "redis",
})
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
err := rdb.Watch(ctx, func(tx *redis.Tx) error {
_, err := tx.TxPipelined(ctx, func(pipe redis.Pipeliner) error {
pipe.Set(ctx, "x", "newValueFromA", 0)
return nil
})
return err
}, "x")
if err != nil {
log.Printf("Goroutine A aborted: %v", err)
} else {
log.Printf("Goroutine A succeeded")
}
}()
go func() {
defer wg.Done()
err := rdb.Watch(ctx, func(tx *redis.Tx) error {
_, err := tx.TxPipelined(ctx, func(pipe redis.Pipeliner) error {
pipe.Set(ctx, "x", "newValueFromB", 0)
return nil
})
return err
}, "x")
if err != nil {
log.Printf("Goroutine B aborted: %v", err)
} else {
log.Printf("Goroutine B succeeded")
}
}()
wg.Wait()
value, err := rdb.Get(ctx, "x").Result()
if err != nil {
log.Fatalf("Could not get x: %v", err)
}
log.Printf("Final value of x: %v", value)
}
/*
2023/09/04 00:06:19 Goroutine A aborted: redis: transaction failed
2023/09/04 00:06:19 Goroutine B succeeded
2023/09/04 00:06:19 Final value of x: newValueFromB
*/
依賴線性一致性
介紹:
線性一致性在什麼情況下有用?觀看體育比賽的最後得分可能是一個輕率的例子:滯後了幾秒鐘的結果不太可能在這種情況下造成任何真正的傷害。然而對於少數領域,線性一致性是系統正確工作的一個重要條件。
鎖定和領導選舉
在單主複製架構中,只有一個領導者(也叫做主節點)負責執行所有寫操作,以預防腦裂現象,即避免多個節點同時認為自己是領導者。為了協調哪個節點可以成為領導者,系統會採用分散式鎖。這種鎖必須要達到線性一致性,也就是所有節點必須共識到誰擁有這把鎖。協調服務像 Apache ZooKeeper 和 etcd 常被用來實現這樣的分散式鎖和領導者選舉。儘管它們提供了線性一致性的寫操作,讀取數據可能仍是過時的,因為這些讀取操作可能由任何一個副本完成。
約束和唯一性保證
在維持關聯式資料庫中的PRIMARY KEY和UNIQUE約束時,通常會使用線性一致性來確保所有節點達到共識。例如,在一個用戶註冊系統中,可能會選擇使用電郵作為唯一識別。如果沒有線性一致性,這可能導致資料不一致或用戶重複註冊。
對於更寬鬆的約束,如FOREIGN KEY,線性一致性不一定是必須的。以電商平台為例,Orders 表與 Products 表是緊密相關的。新商品一旦加入 Products 表,便可能會立即在搜索結果中出現,但相對應的訂單處理(涉及 Orders 表)可能會因為庫存或價格等因素稍微延後。在這樣的情境下,最終一致性會是一個更靈活的選擇。
跨通道的時序依賴
圖9-1中有一個細節:如果Alice沒有喊德國贏了Bob就不會靠腰資料是舊的,是因為這個系統多了一個額外通道(通話)才導致發現線性不一致。
計算機系統也會出現類似的情況。例如,假設有一個網站,使用者可以上傳照片,一個後臺程序會調整照片大小,降低解析度以加快下載速度(縮圖)。該系統的架構和資料流如圖 9-5所示
假設有一個網站使用者上傳照片,後台會縮小照片降低解析度增加下載速度(縮圖)。
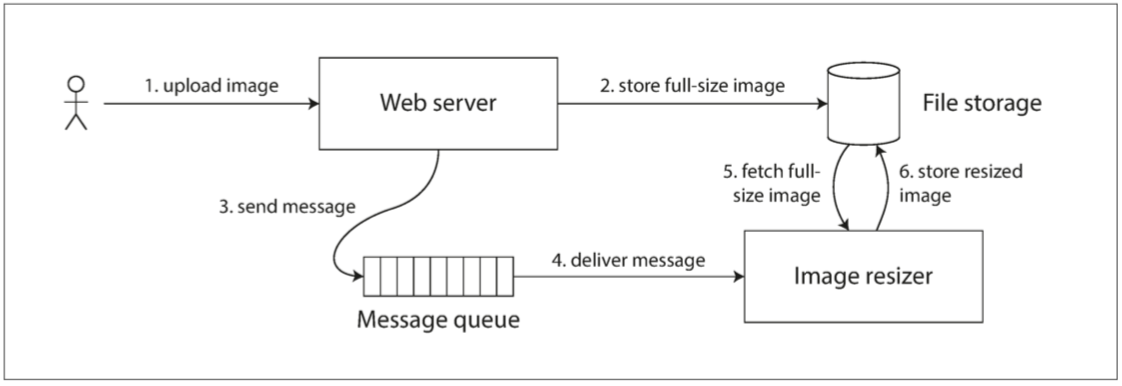
圖 9-5 Web 伺服器和影象縮放器透過檔案儲存和訊息佇列進行通訊,開啟競爭條件的可能性。
描述:
1.使用者上傳照片(1.jpg)到Web server
2.Web server將照片(UUID.jpg)放到File storage(/temp)儲存
3.將一個訊息push到MQ(UUID.jpg,/temp)
4.MQ通知Image resizer要縮小的檔案位置(/temp/UUID.jpg)
5.Image resizer讀取File storage的照片(/temp/UUID.jpg)
6.Image resizer處理完縮小照片後上傳到File storage(/result/UUID.jpg)給使用者下載
如果MQ比File stroage複製的更快,可能會導致步驟5出現舊的影像或沒有影像,如果某個節點處理是舊的影像則就產生了永久性的不一致。
出現這個問題是因為Web server和Image resizer之間存在不同的通道:File storage與MQ,這兩個通道之間有可能產生競爭條件。這種狀況類似Alice與Bob語音通訊與網頁更新也存在了競爭條件。
線性一致性並不是避免這種競爭條件的唯一方法,只是這種方式最容易理解,如果可以透過控制MQ則可以使用第五章(Read-Your-Writes Consistency)類似的方法,但是會有而外的複雜代價。
第五章Read-Your-Writes Consistency ~~*補全~~
當使用者寫入一則評論,有可能重新整理頁面發現剛剛寫入的資料不見了(可能從其他節點讀取但是那個節點根本還沒有被Leader更新),因此使用者困惑了可能會再次寫入剛剛的評論,所以要在寫入Leader的時候直接讀取使用者評論,這樣就可以避免使用者讀取到尚未最終一致性的資料。
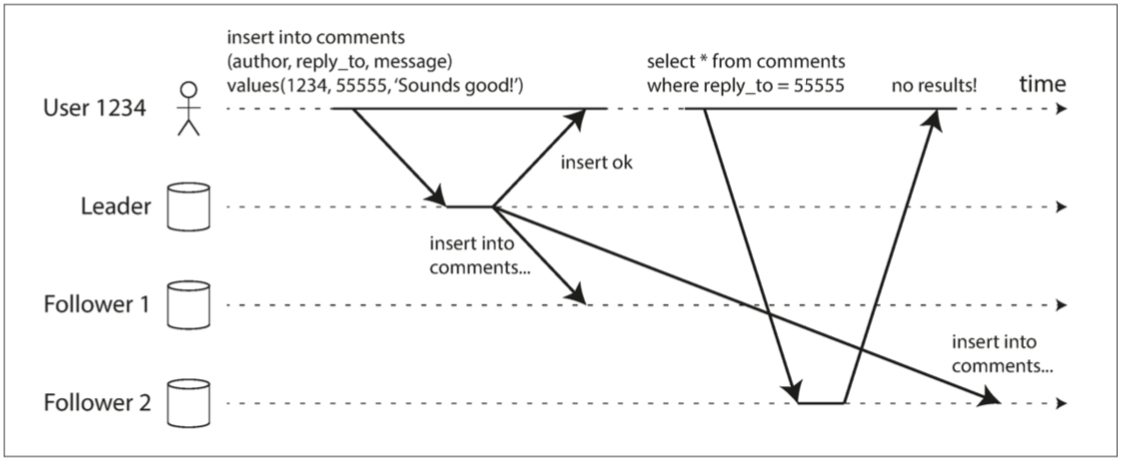
圖 5-3 使用者寫入後從舊副本中讀取資料。需要寫後讀 (read-after-write) 的一致性來防止這種異常
描述:
1.User寫評論到Leader然後
2.使用者去Follower2讀取剛剛的comments並沒有剛剛寫入55555的評論
3.Leader過了一段時間才完成最終一致性這時候User才能取到真剛剛寫入的55555
總結:
可以利用寫入Leader寫入回傳的ok來處理讀自己寫的假資料至少讓他不要去Follower2去查看發現資料不對
實現線性一致的系統
介紹:
由於線性一致性本質上意味著 “表現得好像只有一個數據副本,而且所有的操作都是原子的”,所以最簡單的答案就是,真的只用一個數據副本。但是這種方法無法容錯:如果持有該副本的節點失效,資料將會丟失,或者至少無法訪問,直到節點重新啟動。
使系統容錯最常用的方法是使用複製。我們再來回顧 第五章 中的複製方法,並比較它們是否可以滿足線性一致性:
- 單主複製(可能線性一致)
在具有單主複製功能的系統中(請參閱 “領導者與追隨者”),主庫具有用於寫入的資料的主副本,而追隨者在其他節點上保留資料的備份副本。如果從主庫或同步更新的從庫讀取資料,它們 可能(potential) 是線性一致性的 ^iv。然而,實際上並不是每個單主資料庫都是線性一致性的,無論是因為設計的原因(例如,因為使用了快照隔離)還是因為在併發處理上存在錯誤【10】。
從主庫讀取依賴一個假設,你確切地知道領導者是誰。正如在 “真相由多數所定義” 中所討論的那樣,一個節點很可能會認為它是領導者,而事實上並非如此 —— 如果具有錯覺的領導者繼續為請求提供服務,可能違反線性一致性【20】。使用非同步複製,故障切換時甚至可能會丟失已提交的寫入(請參閱 “處理節點宕機”),這同時違反了永續性和線性一致性。 - 共識演算法(線性一致)
一些在本章後面討論的共識演算法,與單主複製類似。然而,共識協議包含防止腦裂和陳舊副本的措施。正是由於這些細節,共識演算法可以安全地實現線性一致性儲存。例如,Zookeeper 【21】和 etcd 【22】就是這樣工作的。 - 多主複製(非線性一致)
具有多主程式複製的系統通常不是線性一致的,因為它們同時在多個節點上處理寫入,並將其非同步複製到其他節點。因此,它們可能會產生需要被解決的寫入衝突(請參閱 “處理寫入衝突”)。這種衝突是因為缺少單一資料副本所導致的。 - 無主複製(也許不是線性一致的)
對於無主複製的系統(Dynamo 風格;請參閱 “無主複製”),有時候人們會聲稱透過要求法定人數讀寫(w+r>n)可以獲得 “強一致性”。這取決於法定人數的具體配置,以及強一致性如何定義(通常不完全正確)。
基於日曆時鐘(例如,在 Cassandra 中;請參閱 “依賴同步時鐘”)的 “最後寫入勝利” 衝突解決方法幾乎可以確定是非線性一致的,由於時鐘偏差,不能保證時鐘的時間戳與實際事件順序一致。寬鬆的法定人數(請參閱 “寬鬆的法定人數與提示移交”)也破壞了線性一致的可能性。即使使用嚴格的法定人數,非線性一致的行為也是可能的,如下節所示。第五章無主複製
補全
使用者每次都讀寫多個複製件
讀寫法定人數:
公式 w+r>n 讀加寫要大於總結點
因爲n=3 w=2 r=2 所以2+2>3成立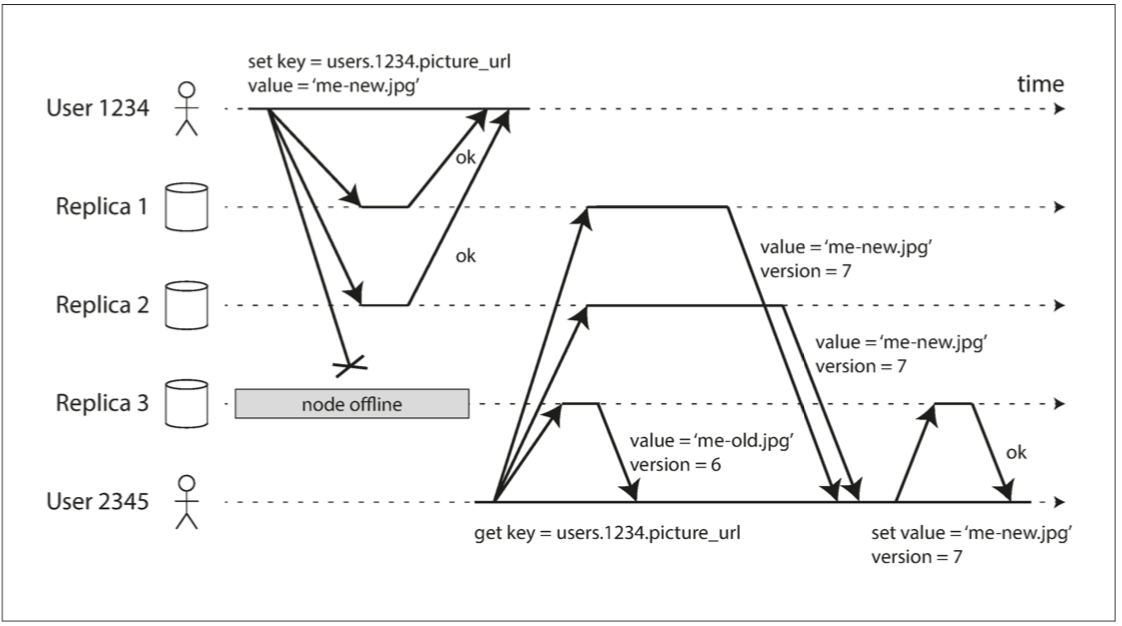
圖 5-10 法定寫入,法定讀取,並在節點中斷後讀修復。
敘述:
1.UserA寫入N1 N2 ‘me-new.jpg’(因為N3死掉了)
2.UserB讀取N1 N2 N3 結果發現N3的版本是6其他是7
3.UserB就將N3 ’me-new.jpg’的version設定成7
結論:
無主複製就是要將監督機制直接寫在使用者身上(應用層)而不是讓資料庫自己去發現
線性一致性和法定人數
介紹:
直覺上無主複製模型中嚴格的法定人數應該是線性一致的。但是當可變的網路延遲就能產生競爭條件。
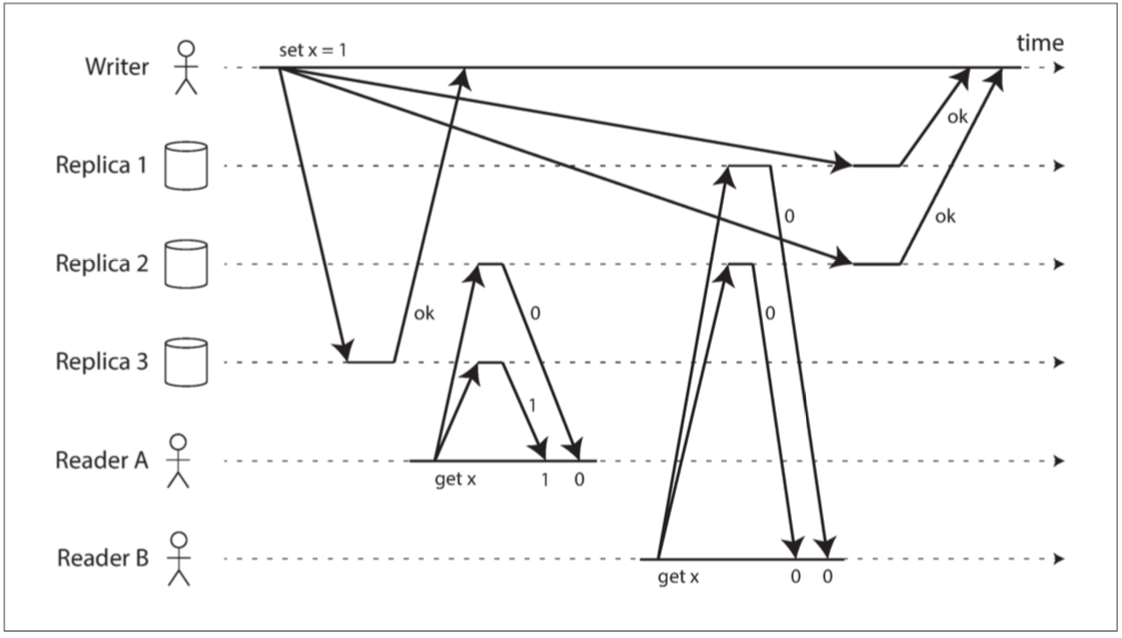
圖 9-6 非線性一致的執行,儘管使用了嚴格的法定人數
敘述:
w = 3 r = 2 n = 3
- x=0
- Writer 寫入x = 1 到 N1 N2 N3(最快寫入)
- ReaderA 讀取N1(X) N2(x=0) N3(x=1)
- ReaderB 讀取N1(x=0) N2(x=0) N3(X)
結論:
就算法定人數正確也無法保證線性一致,所以最安全的做法就是當作無主複製系統不能提供線性一致
線性一致性的代價
介紹:
一些複製方法可以提供線性一致性,另一些複製方法則不能,因此深入地探討線性一致性的優缺點是很有趣的。
我們已經在 第五章 中討論了不同複製方法的一些用例。例如對多資料中心的複製而言,多主複製通常是理想的選擇(請參閱 “運維多個數據中心”)。圖 9-7 說明了這種部署的一個例子。
{kind=link}
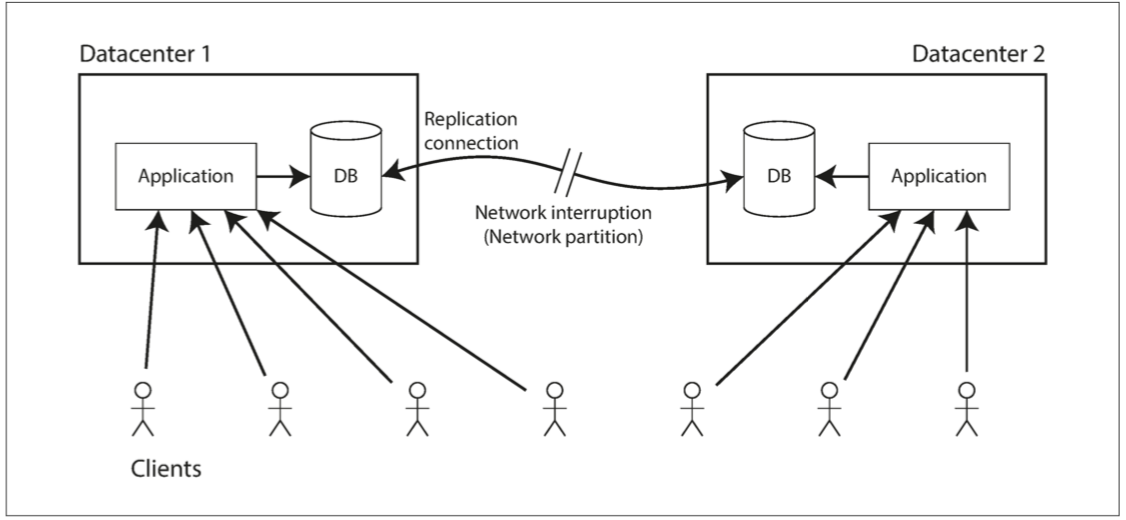
圖 9-7 網路中斷迫使線性一致性和可用性之間做出選擇。
敘述:
多主資料庫:兩個datacenter還是可以單獨使用等到網路恢復後只需要排隊並交換
單主複製:從庫資料中心無法寫入也不能執行任何線性一致的讀取,但是還是可以不使用線性一致的讀取但是讀的資料可能是舊的。
結論:
整體來說不管多主單主都無法避免斷線帶來的線性不一致
CAP定理
介紹:
這個問題不僅僅是單主複製和多主複製的後果:任何線性一致的資料庫都有這個問題,不管它是如何實現的。這個問題也不僅僅侷限於多資料中心部署,而可能發生在任何不可靠的網路上,即使在同一個資料中心內也是如此。問題面臨的權衡如下:
- 如果應用需要線性一致性,且某些副本因為網路問題與其他副本斷開連線,那麼這些副本掉線時不能處理請求。請求必須等到網路問題解決,或直接返回錯誤。(無論哪種方式,服務都 不可用)。
- 如果應用不需要線性一致性,那麼某個副本即使與其他副本斷開連線,也可以獨立處理請求(例如多主複製)。在這種情況下,應用可以在網路問題解決前保持可用,但其行為不是線性一致的。
這兩種選擇有時分別稱為 CP(在網路分割槽下一致但不可用)和 AP(在網路分割槽下可用但不一致)。 但是,這種分類方案存在一些缺陷【9】,所以最好不要這樣用。
補充:
一致性(Consistency):
所有節點在同一時刻可以看到相同的數據。
可用性(Availability):
每次請求都會在有限的時間內收到一個明確的成功或失敗回應。
分區容錯性(Partition tolerance):
即使網絡分區(Partition)發生,系統依然能正常運作。
CAP定理認為必須要在一致性與可用性作出權衡
- 可以有一個 CP(一致性和分區容錯性) 的系統,比如 ZooKeeper。
- 可以有一個 CA(一致性和可用性) 的系統,但這基本上只能在單一節點的情況下實現,一旦涉及到分布式,網絡分區是無法避免的。
- 可以有一個 AP(可用性和分區容錯性) 的系統,比如 Cassandra 或 Couchbase。
線性一致性和網路延遲
1.連cpu上的記憶體都不一定是線性一致性的:
如果一個 CPU 核上執行的執行緒寫入某個記憶體地址,而另一個 CPU 核上執行的執行緒不久之後讀取相同的地址,並沒有保證一定能讀到第一個執行緒寫入的值(除非使用了 記憶體屏障(memory barrier) 或 圍欄(fence)【44】)。
而且CPU核心與核心之間的通訊基本都是正常的狀況下還有可能發生線性不一致性。
2.以CPU來說是為了提高效能而選擇犧牲線性一致性而不是為了容錯
3.可能找不到高效並且線性一致性的系統
9.3 順序保證
介紹:
這小節主要要探討圖9-4順序
- 在 第五章 中我們看到,領導者在單主複製中的主要目的就是,在複製日誌中確定 寫入順序(order of write)—— 也就是從庫應用這些寫入的順序。如果不存在一個領導者,則併發操作可能導致衝突(請參閱 “處理寫入衝突”)。
- 在 第七章 中討論的 可序列化,是關於事務表現的像按 某種先後順序(some sequential order) 執行的保證。它可以字面意義上地以 序列順序(serial order) 執行事務來實現,或者允許並行執行,但同時防止序列化衝突來實現(透過鎖或中止事務)。
- 在 第八章 討論過的在分散式系統中使用時間戳和時鐘(請參閱 “依賴同步時鐘”)是另一種將順序引入無序世界的嘗試,例如,確定兩個寫入操作哪一個更晚發生。
順序與因果關係(因果一致性 causally consistent)
- 5-5一致字首讀:有因果關係
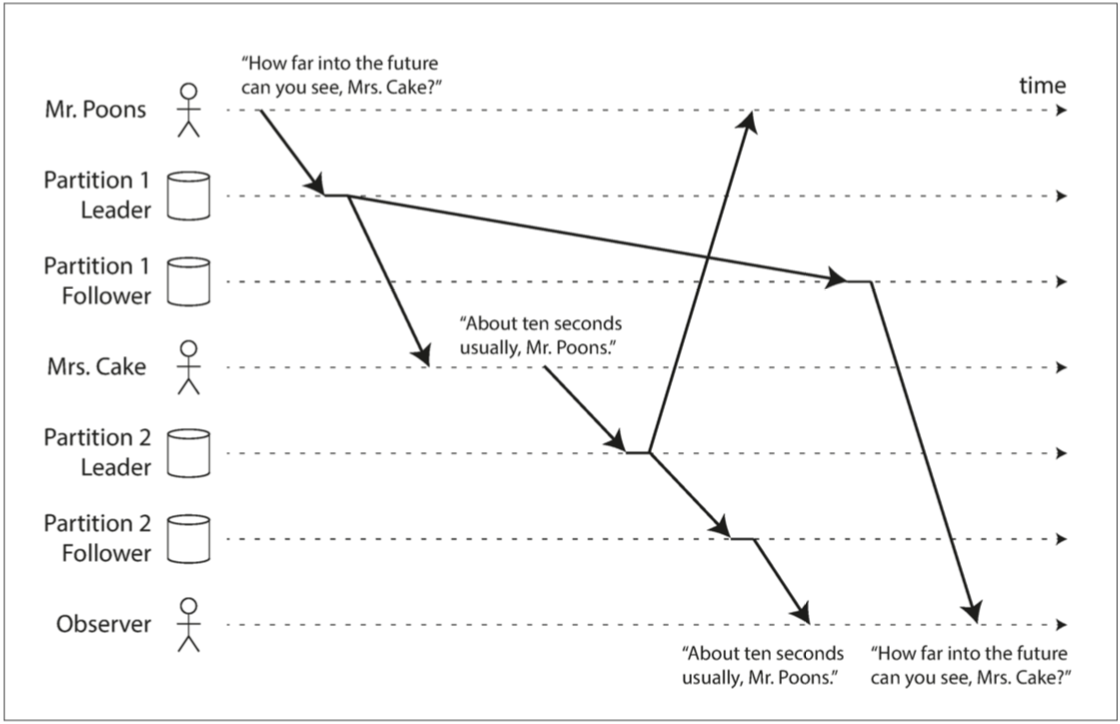
圖 5-5 如果某些分割槽的複製速度慢於其他分割槽,那麼觀察者可能會在看到問題之前先看到答案。
通常,問題和答案之間存在明確的因果關係,因為要回答一個問題,首先要有問題的存在。
因果關係例子:
在一個線上問答社區,通常需要先有人提出問題,然後其他人才能看到並回答這個問題。如果由於網絡延遲,有人先看到了回答而後看到問題,這違反了正常的因果順序。 - 5-9複製和網路延遲:有因果關係
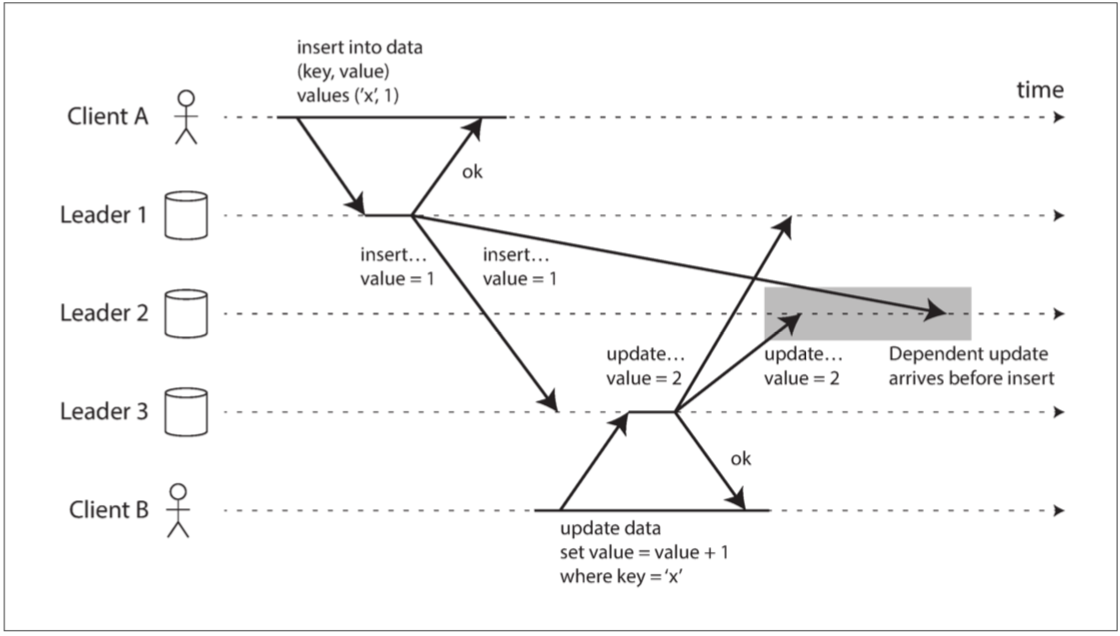
圖 5-9 使用多主複製時,寫入可能會以錯誤的順序到達某些副本。
在這個情境下,明確的因果關係是,一個記錄必須先被創建,然後才能被更新。
因果關係例子:
如果在家中的多台電腦上同步文件,通常必須先在一台電腦上創建文件,然後它才能被同步到其他電腦上。如果由於網絡延遲,文件的更新在某台電腦上先於文件的創建被接收到,這違反了正常的因果順序。 - 檢測併發寫入:有可能有因果關係
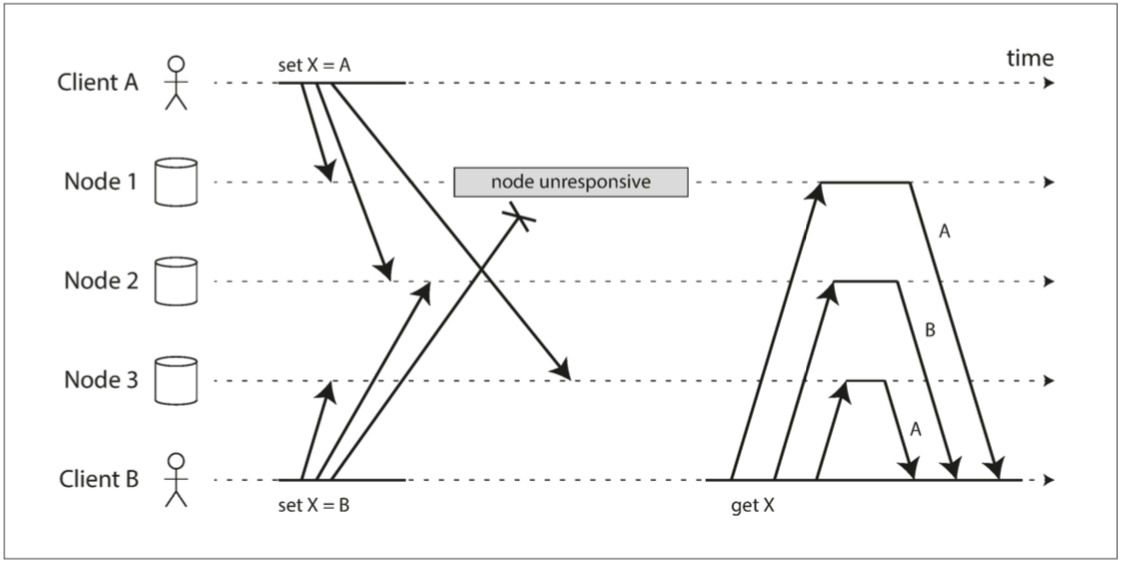
圖 5-12 併發寫入 Dynamo 風格的資料儲存:沒有明確定義的順序。
在這個情境下,可能存在因果關係,例如,如果操作A影響了操作B的結果,那麼就存在因果關係。但如果A和B是獨立並行的,則不存在因果關係。
因果關係例子:
在超市結賬時,如果兩個人同時到達結賬台,需要確定哪個人應該先結賬以保持秩序。這種順序決定了誰先誰後,存在因果關係。 - 事務快照隔離(快照隔離和可重複讀):有因果關係
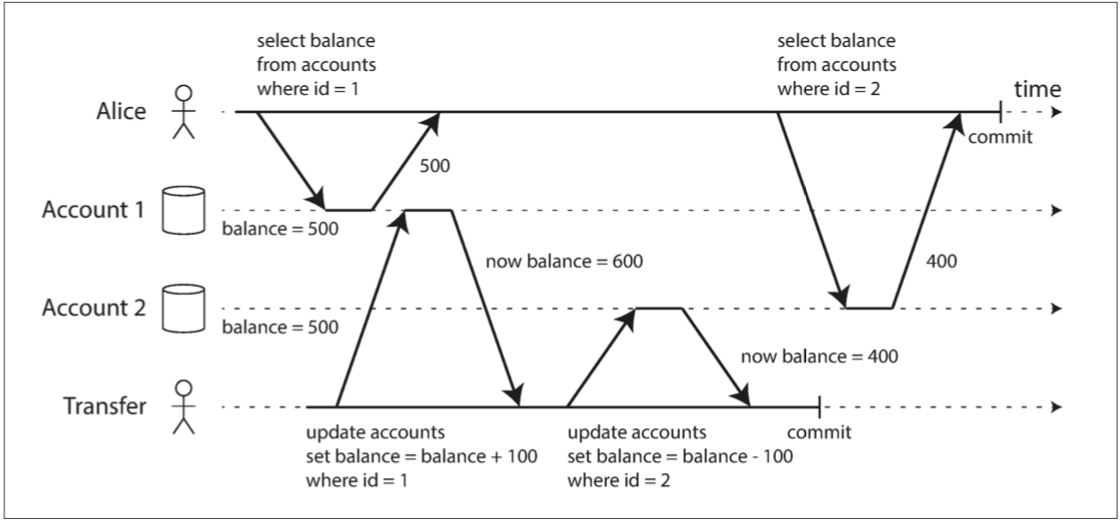
圖 7-6 讀取偏差:Alice 觀察資料庫處於不一致的狀態
不可重複讀,除非知道因果關係要不然重複讀取會產生不一致
因果關係例子:
查看社交媒體的時候看到了一個回覆,理所當然的,你會期望能夠看到被回覆的原始帖子,因為回覆(效果)依賴於原始帖子(原因)。 - 寫偏差(寫入偏差與幻讀):可能有因果關係
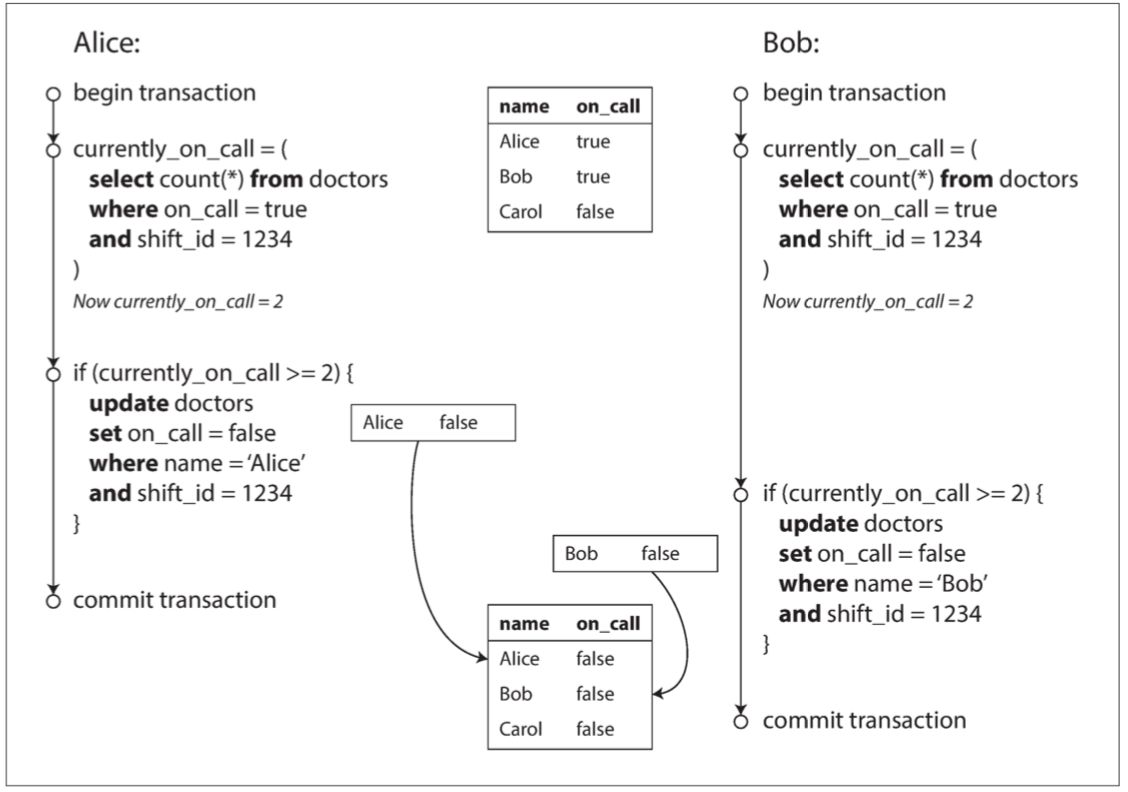
圖 7-8 寫入偏差導致應用程式錯誤的示例
Alice依賴Bob的on_call狀態,Bob也依賴Alice的on_call狀態
寫偏差的情境下可能存在因果關係,例如,某個事務的結果可能依賴於另一個事務的狀態。
因果關係例子:
在一個忙碌的餐廳,如果兩個服務員同時去搶一個空出來的桌子給等待的客人,但由於沒有及時通信,可能會導致兩組客人被安排到同一個桌子,這是因果關係管理的失敗。 - 因果依賴和時序(Alice & Bob 看球賽):有因果關係
圖 9-1 這個系統是非線性一致的,導致了球迷的困惑
在這個情境下,存在明確的因果關係,比如進球(原因)和球員慶祝(效果)。
因果關係例子:
在觀看足球比賽時,球員的慶祝是依賴於先前的進球事件。進球是原因,球員的慶祝是效果,二者之間存在明確的因果關係。
結論:
- 因果一致性:重視操作之間的因果關係。如果操作A在因果上先於操作B,那麼系統應保證所有節點上A的效果都會在B的效果之前被看到。這使得系統能夠保留操作的自然順序,但不保證全局的操作順序。
- 線性一致性:要求系統中的所有操作都能夠按照某一全局順序(通常是時間順序)來呈現,使得所有操作看起來就像是在一個單一的、原子的、全局順序的時間點上發生的。這提供了一個非常強的一致性保證,但可能會降低系統的性能和可用性。
因果順序不是全序的
全序(total order): 允許任意兩個元素進行比較,所以如果有兩個元素,你總是可以說出哪個更大,哪個更小。例如,自然數集是全序的:給定兩個自然數,比如說 5 和 13,那麼你可以知道,13 大於 5。
偏序(partially ordered):考慮三個集合:A={1,2},B={2,3},和C={1,2,3}。在這裡,A和B是無法比較的,因為它們之間沒有子集關係。但是,A和C可以比較,因為A是C的子集,記作A⊂C。
全序和偏序之間的差異反映在不同的資料庫一致性模型中:
- 線性一致性
線性一致的系統中,操作是全序的:如果系統表現的就好像只有一個數據副本,並且所有操作都是原子性的,這意味著對任何兩個操作,我們總是能判定哪個操作先發生。這個全序在 圖 9-4 中以時間線表示。 - 因果性
我們說過,如果兩個操作都沒有在彼此 之前發生,那麼這兩個操作是併發的(請參閱 “此前發生” 的關係和併發)。換句話說,如果兩個事件是因果相關的(一個發生在另一個事件之前),則它們之間是有序的,但如果它們是併發的,則它們之間的順序是無法比較的。這意味著因果關係定義了一個偏序,而不是一個全序:一些操作相互之間是有順序的,但有些則是無法比較的。併發是偏序的
{kind=link}
graph TD;
全序
A[任務 A];
B[任務 B];
C[任務 C];
D[任務 D];
E[任務 E];
全序 --> A;
A --> B;
B --> C;
C --> D;
D --> E;
偏序
A1[任務 A];
B1[任務 B];
C1[任務 C];
D1[任務 D];
E1[任務 E];
F1[任務 F];
偏序-->A1;
A1 --> B1;
B1 --> D1;
A1 --> C1;
C1 --> E1;
D1 --> F1;
E1 --> F1;
如果你熟悉像 Git 這樣的分散式版本控制系統,那麼其版本歷史與因果關係圖極其相似。通常,一個 提交(Commit) 發生在另一個提交之後,在一條直線上。但是有時你會遇到分支(當多個人同時在一個專案上工作時),合併(Merge) 會在這些併發建立的提交相融合時建立。因為知道develop發生過什麼事情再去看5-22e4a46才知道是全序的
gitGraph:
options
{
"nodeSpacing": 150,
"nodeRadius": 10
}
end
commit
commit
branch develop
checkout develop
commit
commit
checkout main
merge develop
commit
commit
線性一致性強於因果一致性
線性一致性隱含了因果關係,也就是說,任何線性一致的系統都能正確地保持因果性,即使在有多個通訊通道的情況下也能自動保證,無需進行特殊的操作如傳遞時間戳。這種隱含的關係使得線性一致性成為了一個非常強大而又直觀的一致性模型。
許多分散式系統看起來需要線性一致性但實際上只要保證網路不延遲其實使用因果一致性就算是最強的一致性模型。
捕獲因果關係
為了保持因果性,系統必須能夠識別操作間的“發生在先前”(happened before)關係。這形成了一種偏序(partial ordering)關係,意味著在某些情況下,可以明確地說一個操作發生在另一個操作之前,而在其他情況下(如併發操作),則無法做出此判定。
為了明確因果依賴,需要有方式描述系統中各節點的“知識”。這種“知識”是指節點在進行某些操作時,對系統中其他事件的了解。例如,如果一個節點在發出寫入Y的請求時已經看到了X的值,那麼就可能存在一個因果關係,表示X是Y發生的原因。這種情況類似於在欺詐指控的刑事調查中常見的問題,例如在做出某個決定Y時,CEO是否知道了X的情況。在這種情況下,X和Y之間的因果關係是基於節點(或在刑事調查中的CEO)在執行操作時所具有的知識。這種分析方式可以幫助確定事件之間的因果依賴,並且對於維持系統的因果一致性至關重要。
為了確定因果順序,資料庫需要知道應用讀取了哪個版本的資料。這就是為什麼在 圖 5-13 中,來自先前操作的版本號在寫入時被傳回到資料庫的原因。在 SSI 的衝突檢測中會出現類似的想法,如 “可序列化快照隔離” 中所述:當事務要提交時,資料庫將檢查它所讀取的資料版本是否仍然是最新的。為此,資料庫跟蹤哪些資料被哪些事務所讀取。
{kind=link}
結論:
我們可以從資料庫的版本“知識點”來捕獲因果關係,由於這個知識是找出因果的關鍵所以可能會製造出衝突讓多節點系統保持一致性
序列號順序
雖然因果是一個重要的理論概念,但是要跟蹤所有的因果關係是不切實際的,還好有一個更好的方法,我們可以使用 序列號(sequence number) 或 時間戳(timestamp) 來排序事件,時間戳不一定要來自於日曆時鐘,可以用使用邏輯時鐘,因為日曆時鐘會有“不可靠時鐘”問題,典型的邏輯時鐘實現是使用每次操作自增計數器。
使用自增計數器可以提供比較值越大的後發生,我們可以使用因果一致的全序來產生序列號,這樣就可以產生一個比因果性更嚴格的順序。
一個因果關係不一致的全序很容易建立但是是垃圾,例如我們隨機產生了一個UUID但是這個序列根本沒辦法為我們提供操作的先後順序,或者是否觀察的出來操作是否是併發的。
在單主複製的資料庫中,複製日誌定義因果一致的寫操作,主庫可以為每個動作採用自增計數,而從每個操作分配一個遞增的序列號。如果一個從庫按照複製日誌的順序來寫入,這樣一來從庫的狀態會始終是因果一致的。就算從庫落後於領導者也能保持因果一致,因為有複製日誌的序列讓從庫知道先後順序該如何寫入。
sequenceDiagram
participant 主庫
participant 複製日誌
participant 從庫
主庫->>複製日誌: 操作1 (序列號: 1)
複製日誌-->>從庫: 操作1 (序列號: 1)
主庫->>複製日誌: 操作2 (序列號: 2)
複製日誌-->>從庫: 操作2 (序列號: 2)
主庫->>複製日誌: 操作3 (序列號: 3)
複製日誌-->>從庫: 操作3 (序列號: 3)
非因果序列號生成器
如果主庫不存在(可能因為使用了多主資料庫或無主資料庫,或者因為使用了分割槽的資料庫),如何為操作生成序列號就沒有那麼明顯了。在實踐中有各種各樣的方法:
- 每個節點都可以生成自己獨立的一組序列號。例如有兩個節點,一個節點只能生成奇數,而另一個節點只能生成偶數。通常,可以在序列號的二進位制表示中預留一些位,用於唯一的節點識別符號,這樣可以確保兩個不同的節點永遠不會生成相同的序列號。
sequenceDiagram participant Node1 as 節點1 (奇數序列號) participant Node2 as 節點2 (偶數序列號) Note over Node1,Node2: 每個節點可以生成自己獨立的一組序列號 Node1->>Node2: 操作1 (序列號: 1) Node2->>Node1: 操作2 (序列號: 2) Node1->>Node2: 操作3 (序列號: 3) Node2->>Node1: 操作4 (序列號: 4) Note over Node1,Node2: 兩個不同的節點永遠不會生成相同的序列號 - 可以將日曆時鐘(物理時鐘)的時間戳附加到每個操作上【55】。這種時間戳並不連續,但是如果它具有足夠高的解析度,那也許足以提供一個操作的全序關係。這一事實應用於* 最後寫入勝利 * 的衝突解決方法中(請參閱 “有序事件的時間戳”)。
”最後只有操作三可以成功寫入”
sequenceDiagram participant Node1 as 節點1 participant Node2 as 節點2 Note over Node1,Node2: 操作依賴物理時鐘 Node1->>Node2: 操作1 (時間戳: 08:00:00) Node2->>Node1: 操作2 (時間戳: 08:01:00) Node1->>Node2: 操作3 (時間戳: 08:02:00) Note over Node1, Node2: 最後只有操作三可以成功寫入 - 可以預先分配序列號區塊。例如,節點 A 可能要求從序列號 1 到 1,000 區塊的所有權,而節點 B 可能要求序列號 1,001 到 2,000 區塊的所有權。然後每個節點可以獨立分配所屬區塊中的序列號,並在序列號告急時請求分配一個新的區塊。
sequenceDiagram participant NodeA as 節點A participant NodeB as 節點B Note over NodeA,NodeB: 預先分配序列號區塊 NodeA->>NodeB: 操作1 (序列號: 500) NodeB->>NodeA: 操作2 (序列號: 1500) NodeA->>NodeB: 操作3 (序列號: 800) NodeB->>NodeA: 操作4 (序列號: 1600)
這三個選項都比單一主庫的自增計數器表現要好,並且更具可伸縮性。它們為每個操作生成一個唯一的,近似自增的序列號。然而它們都有同一個問題:生成的序列號與因果不一致。- 每個節點每秒可以處理不同數量的操作。因此,如果一個節點產生偶數序列號而另一個產生奇數序列號,則偶數計數器可能落後於奇數計數器,反之亦然。如果你有一個奇數編號的操作和一個偶數編號的操作,你無法準確地說出哪一個操作在因果上先發生。
sequenceDiagram participant Node1 as 節點1 (奇數序列號) participant Node2 as 節點2 (偶數序列號) Note over Node1,Node2: 每個節點每秒可以處理不同數量的操作 Node1->>Node2: 操作1 (序列號: 1, 時間: 08:00:00) Note over Node1: 節點1 快速處理操作 Node1->>Node2: 操作3 (序列號: 3, 時間: 08:00:01) Note over Node2: 節點2 較慢地處理操作 Node2->>Node1: 操作2 (序列號: 2, 時間: 08:00:05) Node2->>Node1: 操作4 (序列號: 4, 時間: 08:00:10) Note over Node1,Node2: 無法確定操作2和操作3哪個在因果上先發生 - 來自物理時鐘的時間戳會受到時鐘偏移的影響,這可能會使其與因果不一致。例如 圖 8-3 展示了一個例子,其中因果上晚發生的操作,卻被分配了一個更早的時間戳。可以使物理時鐘時間戳與因果關係保持一致:在 “全域性快照的同步時鐘” 中,我們討論了 Google 的 Spanner,它可以估計預期的時鐘偏差,並在提交寫入之前等待不確定性間隔。這種方法確保了實際上靠後的事務會有更大的時間戳。但是大多數時鐘不能提供這種所需的不確定性度量。
sequenceDiagram participant Node1 as 節點1 participant Node2 as 節點2 Note over Node1,Node2: 時鐘偏移影響 Node1->>Node2: 操作1 (時間戳: 10:00:01) Node2->>Node1: 操作2 (時間戳: 10:00:00, 因果上晚於操作1) Note over Node1,Node2: 因果關係與時間戳不一致 - 在分配區塊的情況下,某個操作可能會被賦予一個範圍在 1,001 到 2,000 內的序列號,然而一個因果上更晚的操作可能被賦予一個範圍在 1 到 1,000 之間的數字。這裡序列號與因果關係也是不一致的。
sequenceDiagram participant NodeA as 節點A participant NodeB as 節點B Note over NodeA,NodeB: 序列號與因果不一致 NodeA->>NodeB: 操作1 (序列號: 1500) NodeB->>NodeA: 操作2 (序列號: 500, 因果上晚於操作1) Note over NodeA,NodeB: 因果關係與序列號不一致
- 每個節點每秒可以處理不同數量的操作。因此,如果一個節點產生偶數序列號而另一個產生奇數序列號,則偶數計數器可能落後於奇數計數器,反之亦然。如果你有一個奇數編號的操作和一個偶數編號的操作,你無法準確地說出哪一個操作在因果上先發生。
{kind=link}
蘭伯特時間戳
儘管剛才描述的三個序列號生成器與因果不一致,但實際上有一個簡單的方法來產生與因果關係一致的序列號。它被稱為蘭伯特時間戳,萊斯利・蘭伯特(Leslie Lamport)於 1978 年提出【56】
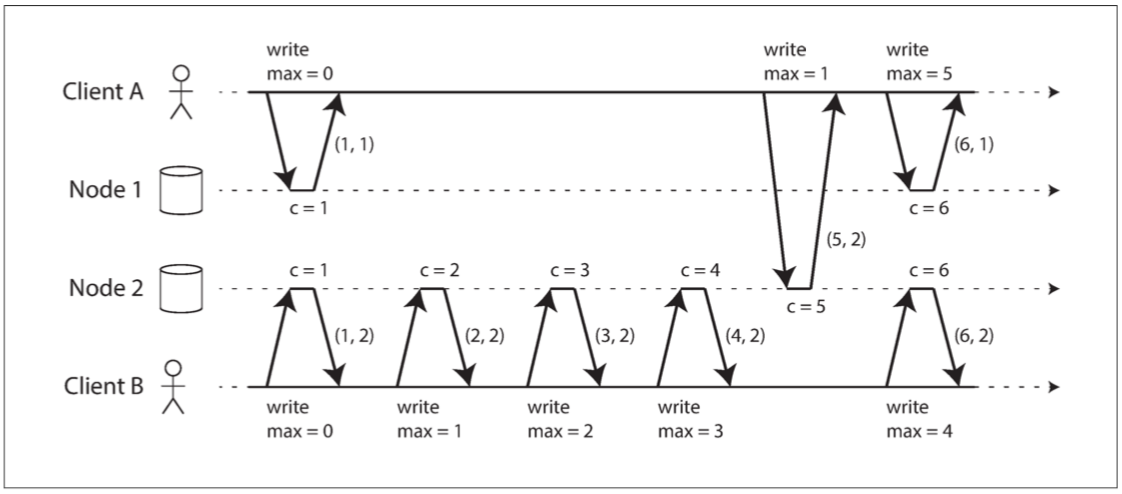
圖 9-8 Lamport 時間戳提供了與因果關係一致的全序。
目標:
Client(Count節點計數器,Node節點名稱) → 使用者攜帶個節點最大值並且在操作兩個節點時更新節點最大值
解說:
每次被操作Node1 與 Node2都會c都會+1,ClientA先存取Node1所以Node1 c=1 中間一段時間都是ClientB存取Node2不管存取幾次因為Node2的C持續的增加,只要ClinetA某次存取到Node2就可以因為讀取到Node2的c而去更新自己的最大值
EX:ClientA(1,1)→ClientA(5,2)→因為曾經讀取過Node2的最大計數值所以ClientA可以更新Node1的c=6,最後產生ClientA(6,1) 因為使用這樣的計數方式可以看得出彼此的因果關係
| ClinetA | ClientB |
|---|---|
| (1,1) | (1,2) |
| (5,2) | (2,2) |
| (6,1) | (3,2) |
| (4,2) | |
| (6,2) |
就算不看圖以資料形式看待也大概猜的的出來兩個Node之間有版本差異
光有時間戳排序還不夠
雖然蘭伯特時間戳定義了一個與因果一致的全序,但它還不足以解決分散式系統中的許多常見問題。
例如:
同時間有兩個使用者要創建同一個名稱的帳號Alice
sequenceDiagram
participant User1 as 使用者1
participant User2 as 使用者2
participant NodeA as 節點A
participant NodeB as 節點B
Note over User1,User2: 嘗試創建相同的使用者名稱
User1->>NodeA: 請求創建帳戶 (使用者名稱: Alice)
User2->>NodeB: 請求創建帳戶 (使用者名稱: Alice)
Note over NodeA,NodeB: 生成蘭伯特時間戳
NodeA->>NodeB: 通知創建請求 (使用者名稱: Alice, 蘭伯特時間戳: L1)
Note right of NodeB: 網路延遲
NodeB->>NodeA: 通知創建請求 (使用者名稱: Alice, 蘭伯特時間戳: L2)
Note right of NodeA: 網路延遲
Note over NodeA,NodeB: 由於網路問題,節點無法準確比較蘭伯特時間戳,無法確定哪個請求先來。
alt 網路恢復
NodeA->>NodeB: 重新通知創建請求 (使用者名稱: Alice, 蘭伯特時間戳: L1)
NodeB->>NodeA: 重新通知創建請求 (使用者名稱: Alice, 蘭伯特時間戳: L2)
Note over NodeA,NodeB: 現在可以比較蘭伯特時間戳,但已經太遲了。
else 網路未恢復
Note over NodeA,NodeB: 系統被拖至停機,無法解決請求。
end
- 請求發送: 使用者1和使用者2分別向節點A和節點B發送請求,試圖創建使用相同名稱的帳戶。
- 生成蘭伯特時間戳: 節點A和節點B在接收到請求時生成蘭伯特時間戳。假設節點A生成的時間戳為L1,節點B生成的時間戳為L2。
- 嘗試通知: 節點A嘗試通知節點B它的請求和時間戳L1,而節點B嘗試通知節點A它的請求和時間戳L2。
- 網路延遲: 由於網路延遲或其他網路問題,這些通知可能會延遲到達,或者可能根本無法到達(節點A與節點B之間的網路延遲)。這使得節點之間無法立即比較蘭伯特時間戳,也就無法確定哪個請求先到來。
- 網路恢復(如果恢復的話): 如果網路最終恢復,節點A和節點B可以重新通知對方它們的請求和蘭伯特時間戳。現在,它們可以比較蘭伯特時間戳來確定哪個請求先到來。但是,這可能已經太遲了,因為使用者可能已經不再等待,或者系統可能已經因其他原因而進入不一致的狀態。
- 網路未恢復: 如果網路未能恢復,節點A和節點B無法確定哪個請求先到來,這可能導致系統被拖至停機,無法解決這些請求。
結論:
即使使用了蘭伯特時間戳(Lamport Timestamps)來確定全序關係,仍然會因為操作的不確定性導致並不完全全序。只有在所有的操作都被收集後,操作的全序才會出現。如何確定全序關係已經塵埃落定,這將在 全序廣播 一節中詳細說明。
全序廣播
介紹:
- 單CPU核心的操作順序:當程式在單個CPU核心上運行時,定義操作的全序相對簡單,因為操作的順序就是它們被CPU執行的順序。
- 分散式系統的操作順序:在分散式系統中,各節點可能在不同的時間執行操作,使得確定全域性操作順序變得困難。
- 時間戳或序列號排序的局限性:雖然可以通過時間戳或序列號來排序操作,但是這種方法不如單主複製有效,尤其是在需要確保唯一性時。
- 單主複製:單主複製通過選擇一個節點作為主庫來確定操作的全序,並在主庫的單個CPU核心上對所有操作進行排序。
- 吞吐量和故障恢復的挑戰:
- 如果系統的吞吐量需求超過了單個主庫的處理能力,則需要考慮如何擴展系統。
- 如果主庫失效,則需要考慮如何進行故障切換,以保證系統的持續運行。
- 全序廣播和原子廣播:這兩種技術旨在解決分散式系統中的全序問題,確保所有節點都以相同的順序看到所有操作,即使在面對節點失效或網路問題的時候也能保持一致性。
全序廣播必須滿足兩個條件:
1.可靠交付
沒有訊息丟失:如果訊息被傳遞到一個節點,它將被傳遞到所有節點。
2.全序交付
訊息以相同的順序傳遞給每個節點。
正確的全序廣播演算法必須始終保證可靠性和有序性,即使節點或網路出現故障。當然在網路中斷的時候,訊息是傳不出去的,但是演算法可以不斷重試,以便在網路最終修復時,訊息能及時透過並送達(當然它們必須仍然按照正確的順序傳遞)。
使用全序廣播
- 共識服務與全序廣播:
- 類似 ZooKeeper 和 etcd 的共識服務實際上實現了全序廣播,顯示了全序廣播與共識之間的密切聯繫。
- 資料庫複製:
- 全序廣播是資料庫複製所需的,每個訊息代表一次資料庫的寫入,所有副本按相同的順序處理相同的寫入,保證副本間的一致性,這被稱為狀態機複製。
- 可序列化的事務:
- 使用全序廣播可以實現可序列化的事務,每個訊息代表一個確定性事務,並且每個節點以相同的順序處理這些訊息,保證資料庫的分割槽和副本的一致性。
- 訊息順序的固化:
- 在全序廣播中,訊息順序在訊息送達時被固化,不允許追溯地將訊息插入順序中的較早位置,使全序廣播比時間戳排序更強。
- 日誌的建立:
- 全序廣播也是建立日誌的一種方式,傳遞訊息就像追加寫入日誌,所有節點必須以相同的順序傳遞相同的訊息,以確保所有節點都可以讀取日誌並看到相同的訊息序列。
- 防護令牌的鎖服務:
- 在實現提供防護令牌的鎖服務中,全序廣播也非常有用。每個獲取鎖的請求都作為一條訊息追加到日誌末尾,並按日誌中的順序依次編號,這些序列號可以作為防護令牌使用。
使用全序廣播實現線性一致的儲存
- 基於全序廣播建立線性一致儲存:
- 全序廣播保證訊息以固定的順序可靠地傳送,而線性一致性則保證讀取能看見最新的寫入值。基於全序廣播,可以構建線性一致的儲存系統。
- 利用 CAS (比較並設定) 原子操作:
- 對每個可能的使用者名稱,創建一個帶有 CAS 原子操作的線性一致暫存器,以確保使用者名稱的唯一性。
- 僅追加日誌的全序廣播:
- 以僅追加日誌的形式實現全序廣播,並通過在日誌中追加和讀取訊息來實現線性一致的 CAS 操作。
- 處理併發寫入:
- 由於日誌項以相同的順序送達所有節點,可以選擇衝突寫入中的第一個作為勝利者,並中止後來者,以此確保所有節點對某個寫入是提交還是中止達成一致。
- 線性一致的讀取:
- 為了使讀取也線性一致,可以選擇:
- 在日誌中追加訊息並等待該訊息被讀回來執行實際的讀取操作;
- 查詢最新日誌訊息的位置,等待所有訊息傳達後再執行讀取;
- 或從同步更新的副本中進行讀取以確保結果是最新的。
- 為了使讀取也線性一致,可以選擇:
結論:
全序廣播就是確保所有電腦(節點)收到的訊息順序都是一樣的,好比是把訊息按照1、2、3、4的順序發給每台電腦,讓每台電腦都按照這個順序來處理事情。這樣做的好處是,當多人同時要求做某件事(比如同時要求建立同一個使用者名稱的帳戶)時,全序廣播可以確定一個固定的順序來處理這些要求,避免亂七八糟的情況發生。也能確保即便網路有延遲,訊息還是能按照正確的順序被送達和處理。全序廣播也能支援一些特定的操作,比如比較然後設定(CAS),確保這些操作能正確無誤地完成。最後,全序廣播通過讓所有電腦按照相同的順序來處理事情,使得每台電腦的狀態都能保持一致。所以,全序廣播是實現線性一致儲存(讓所有電腦的資料保持一致)的一個重要方法。
使用線性一致性儲存實現全序廣播
- 利用線性一致性儲存實現全序廣播的方法:
- 利用線性一致的暫存器儲存一個整數,並提供原子的自增並返回操作或原子CAS操作。
- 對於每個要透過全序廣播發送的訊息,首先執行自增並返回操作,獲得一個序列號,然後將此序列號附加到訊息中。
- 之後將訊息傳送到所有節點,收件人按照序列號的順序依序傳遞訊息。
- 與蘭伯特時間戳的區別:
- 自增線性一致性暫存器獲得的是一個沒有間隙的序列,與蘭伯特時間戳的隨機序列不同,這是全序廣播和時間戳排序間的關鍵區別。
- 實現困難:
- 在單節點情況下實現線性一致性暫存器相對簡單,但在分散式環境中,特別是當節點出錯或網路連接中斷時,實現變得困難。
- 要實現原子性的自增並返回操作,需要深入思考線性一致性的序列號生成器,並可能需要一個共識演算法。
- 與共識問題的關聯:
- 線性一致的CAS或自增並返回暫存器與全序廣播都與共識問題等價,意味著解決了其中一個問題,就可以轉化為解決其他問題的方案。
結論:
利用線性一致性儲存來做全序廣播就是,先有一個特別的儲存空間,它能夠自動增加一個數字,每當有新訊息要發送時,就先讓這個數字加一,然後把這個數字貼到訊息上,接著把訊息發給所有的電腦節點。這樣,每個電腦節點收到訊息時,就按照貼在訊息上的數字順序來處理它們。如果發現有數字跳號了,就先等一下,直到收到缺的那個訊息。如果在這過程中,有電腦節點出了問題或是網路有問題,也有辦法找回並繼續增加那個數字,保證不會亂掉順序。
兩者比較:
使用全序廣播實現線性一致的儲存,就像是有一個郵差負責把信依照特定的順序送到大家手上,每個人都按照收信的順序來讀信,這樣就保證了大家都有相同的理解。這個郵差就像是全序廣播,他保證信件按照一定的順序送到每個人手上,而每個人的儲存空間就像是他們手中的信件,按照順序來讀和理解。
使用線性一致性儲存實現全序廣播,就像是大家都有一個共用的信箱,每個人都可以在裡面放信,但信箱有一個特殊的鎖,只允許按照一定的順序打開來取信。這個信箱就是線性一致性儲存,它保證大家按照一定的順序來放入和取出信件,而全序廣播就是透過這個信箱來保證信件的順序。
簡單來說,前者是靠郵差(全序廣播)來保證信件順序,讓儲存保持一致;後者是靠信箱(線性一致性儲存)來保證信件順序,進而實現全序廣播。
蘭伯特時間戳VS全序廣播
sequenceDiagram
participant User1 as 使用者1
participant User2 as 使用者2
participant NodeA as 節點A
participant NodeB as 節點B
Note over User1,User2: 嘗試創建相同的使用者名稱
User1->>NodeA: 請求創建帳戶 (使用者名稱: Alice)
User2->>NodeB: 請求創建帳戶 (使用者名稱: Alice)
Note over NodeA,NodeB: 生成蘭伯特時間戳
NodeA->>NodeB: 通知創建請求 (使用者名稱: Alice, 蘭伯特時間戳: L1)
Note right of NodeB: 網路延遲
NodeB->>NodeA: 通知創建請求 (使用者名稱: Alice, 蘭伯特時間戳: L2)
Note right of NodeA: 網路延遲
Note over NodeA,NodeB: 由於網路問題,節點無法準確比較蘭伯特時間戳,無法確定哪個請求先來。
alt 網路恢復
NodeA->>NodeB: 重新通知創建請求 (使用者名稱: Alice, 蘭伯特時間戳: L1)
NodeB->>NodeA: 重新通知創建請求 (使用者名稱: Alice, 蘭伯特時間戳: L2)
Note over NodeA,NodeB: 現在可以比較蘭伯特時間戳,但已經太遲了。
else 網路未恢復
Note over NodeA,NodeB: 系統被拖至停機,無法解決請求。
end
sequenceDiagram
participant User1 as 使用者1
participant User2 as 使用者2
participant NodeA as 節點A
participant NodeB as 節點B
participant TotalOrderBroadcast as 全序廣播服務
Note over User1,User2: 嘗試創建相同的使用者名稱
User1->>NodeA: 請求創建帳戶 (使用者名稱: Alice)
User2->>NodeB: 請求創建帳戶 (使用者名稱: Alice)
NodeA->>TotalOrderBroadcast: 發送創建請求 (使用者名稱: Alice)
NodeB->>TotalOrderBroadcast: 發送創建請求 (使用者名稱: Alice)
Note over TotalOrderBroadcast: 全序廣播服務確保所有節點看到相同順序的消息
TotalOrderBroadcast->>NodeA: 傳遞創建請求 (使用者名稱: Alice, 順序: 1)
TotalOrderBroadcast->>NodeB: 傳遞創建請求 (使用者名稱: Alice, 順序: 1)
TotalOrderBroadcast->>NodeA: 傳遞創建請求 (使用者名稱: Alice, 順序: 2)
TotalOrderBroadcast->>NodeB: 傳遞創建請求 (使用者名稱: Alice, 順序: 2)
Note over NodeA,NodeB: 節點根據全序廣播服務的順序處理請求
alt 順序1的請求成功,順序2的請求失敗
NodeA->>User1: 回應請求成功
NodeB->>User2: 回應請求失敗
else 順序2的請求成功,順序1的請求失敗
NodeA->>User1: 回應請求失敗
NodeB->>User2: 回應請求成功
end
9.4 分散式事務與共識
介紹:
共識:目標是讓幾個節點達成一致
領導選舉:
單主複製的資料庫中所有節點需要與某個領導者達成一致,如果一些節點由於網路而故障可能會對領導權歸屬引起爭議。所以共識對於避免錯誤的故障切換至關重要,錯誤的切換會導致兩個節點都認為自己是領導者(腦裂現象)。
原子提交:
在多節點或多分割槽的資料庫中,為保持事務的原子性(全部提交或全部回滾),所有節點需對事務結果達成共識,此問題稱為原子提交。原子提交與共識稍有區別但可相互簡化,非阻塞的原子提交比共識更為困難。
共識的不可能性
介紹:
FLP結果指出,在有節點可能崩潰風險的情況下,無法總是達成共識。這個結果是基於非同步系統模型。然而,若演算法能使用超時或其他方法來識別可能崩潰的節點,或者利用隨機數,共識成為可能。儘管FLP展示了理論上的限制,但現實中的分散式系統通常能達成共識。在探討原子提交問題時,兩階段提交(2PC)演算法常被用來解決,它是一種共識演算法,但不是最佳的。通過學習2PC,可以進一步探索更好的一致性演算法,如ZooKeeper的Zab和etcd的Raft。
原子提交與兩階段提交
介紹:
原子性:
事務的方式通常都是用撤銷或丟棄的方式來解決衝突,原子性可以防止失敗的事物攪亂資料庫,避免了資料庫陷入半成品結果與半更新。
這對多物件事務和維護次級索引的資料庫非常重要,每個次級索引都是與主資料分離的資料結構,因此如果修改了一些資料,則還需要在次級索引中進行相應的更改。
原子性可以確保次級索引與主資料庫保持一致。
從單節點到分散式原子提交
介紹:
在單個數據庫節點執行的事務,原子性通常由儲存引擎實現。
當客戶端請求資料庫節點提交事務時,資料庫將使事務的寫入持久化(通常在預寫式日誌中,請參閱 “讓 B 樹更可靠”),然後將提交記錄追加到磁碟中的日誌裡。如果資料庫在這個過程中間崩潰,當節點重啟時,事務會從日誌中恢復:如果提交記錄在崩潰之前成功地寫入磁碟,則認為事務被提交;否則來自該事務的任何寫入都被回滾。
sequenceDiagram
participant Client as 客戶端
participant Database as 資料庫節點
participant WAL as 預寫式日誌
participant Disk as 磁碟
Client->>Database: 提交事務請求
Database->>WAL: 寫入事務資料
WAL-->>Database: 確認寫入
Database->>Disk: 將提交記錄追加到日誌
Disk-->>Database: 確認寫入
Database-->>Client: 提交成功
alt 崩潰然後重啟
Database->>Disk: 檢查日誌
alt 提交記錄已寫入
Disk-->>Database: 事務已提交
else 提交記錄未寫入
Disk-->>Database: 回滾事務
end
end
單節點:
事務的提交主要取決於資料持久化落盤的 順序:首先是資料,然後是提交記錄。事務提交或終止的關鍵決定時刻是磁碟完成寫入提交記錄的時刻:在此之前,仍有可能中止(由於崩潰),但在此之後,事務已經提交(即使資料庫崩潰)。因此,是單一的裝置(連線到單個磁碟的控制器,且掛載在單臺機器上)使得提交具有原子性。
多節點:
僅向所有節點發送提交請求並獨立提交每個節點的事務是不夠的。這樣很容易發生違反原子性的情況:提交在某些節點上成功,而在其他節點上失敗:
- 某些節點可能會檢測到違反約束或衝突,因此需要中止,而其他節點則可以成功進行提交。假設某個節點已經有某個唯一鍵所以被迫停止某些節點因為沒有違反則成功
- 某些提交請求可能在網路中丟失,最終由於超時而中止,而其他提交請求則通過。順序會有問題
- 在提交記錄完全寫入之前,某些節點可能會崩潰,並在恢復時回滾,而其他節點則成功提交。
如果某些節點提交了事務,但其他節點卻放棄了這些事務,那麼這些節點就會彼此不一致。而且一旦在某個節點上提交了一個事務,如果事後發現它在其它節點上被中止了,它是無法撤回的。出於這個原因,一旦確定事務中的所有其他節點也將提交,節點就必須進行提交。
sequenceDiagram
participant 節點1
participant 節點2
participant 節點3
節點1->>節點2: 嘗試提交事務
節點1->>節點3: 嘗試提交事務
Note right of 節點3: 事務已提交
節點2->>節點1: 放棄事務
Note right of 節點1: 事務已放棄
Note left of 節點2: 節點間存在不一致狀態
事務提交必須是不可撤銷的 ,事務提交之後,不能改變主意,並追溯性地中止事務。這個規則的原因是,一旦資料被提交,其結果就對其他事務可見,因此其他客戶端可能會開始依賴這些資料。這個原則構成了 讀已提交 隔離等級的基礎,在 “讀已提交” 一節中討論了這個問題。如果一個事務在提交後被允許中止,所有那些讀取了 已提交卻又被追溯宣告不存在資料 的事務也必須回滾。
sequenceDiagram
participant 節點
participant 客戶端1
participant 客戶端2
客戶端1->>節點: 提交事務
Note right of 節點: 事務已提交
節點->>客戶端2: 通知已提交事務
客戶端2->>節點: 讀取已提交數據
Note right of 節點: 事務被撤銷(不允許)
節點->>客戶端1: 通知事務被撤銷(錯誤)
節點->>客戶端2: 通知事務被撤銷(錯誤)
雖然還是有辦法在事務事後執行一個補償機制來取消,但從資料庫的角度,跨事務正確性的保證都必須要是應用自己處理。
兩階段提交簡介
介紹:
兩階段提交(two-phase commit) 是一種用於實現跨多個節點的原子事務提交的演算法,即確保所有節點提交或所有節點中止。它是分散式資料庫中的經典演算法。2PC 在某些資料庫內部使用,也以 XA 事務 的形式對應用可用(例如 Java Transaction API 支援)或以 SOAP Web 服務的 WS-AtomicTransaction 形式提供給應用。
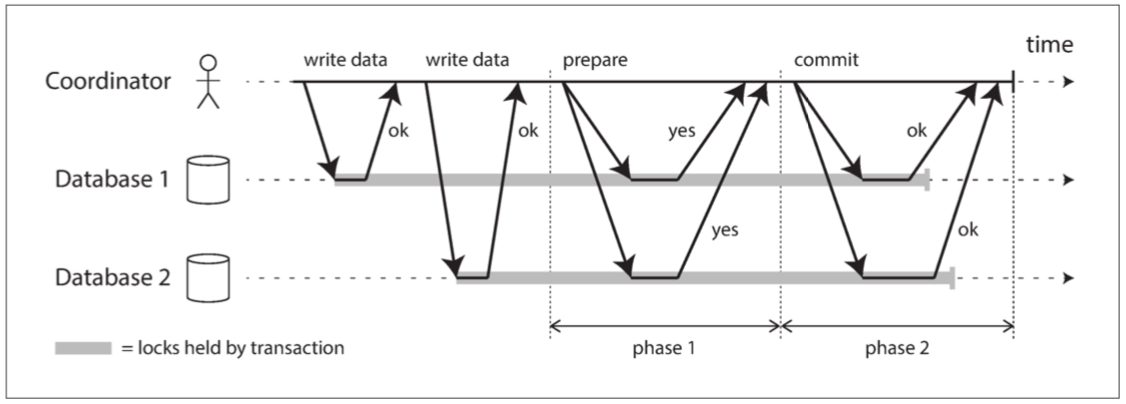
說明了 2PC 的基本流程。2PC 中的提交 / 中止過程分為兩個階段(因此而得名),而不是單節點事務中的單個提交請求。
使用者經過協調者進行通訊,而協調者會進行兩個步驟
1.先跟節點溝通說要寫入資料
2.問各節點準備好了?
3.認後提交
協調者(事務管理器):
1.通常會在多節點事務出現
2.通常以庫的方式實現(Java EE),也可以像是程式或是服務的方式Narayana、JOTM、BTM 或 MSDTC。
參與者:
1.資料庫節點在於2PC通常會稱為餐與者
比喻:
西方傳統結婚儀式
1.牧師先問雙方是否要結婚(雙方是否都在)
2.雙方回復”我願意”
3.牧師宣布正式成為夫妻
系統承諾
2PC之所以可以保證原子性解說:
- 當應用想要啟動一個分散式事務時,它向協調者請求一個事務 ID。此事務 ID 是全域性唯一的。
- 應用在每個參與者上啟動單節點事務,並在單節點事務上捎帶上這個全域性事務 ID。所有的讀寫都是在這些單節點事務中各自完成的。如果在這個階段出現任何問題(例如,節點崩潰或請求超時),則協調者或任何參與者都可以中止。
- 當應用準備提交時,協調者向所有參與者傳送一個 準備 請求,並打上全域性事務 ID 的標記。如果任意一個請求失敗或超時,則協調者向所有參與者傳送針對該事務 ID 的中止請求。
- 參與者收到準備請求時,需要確保在任意情況下都的確可以提交事務。這包括將所有事務資料寫入磁碟(出現崩潰、電源故障或硬碟空間不足都不能是稍後拒絕提交的理由)以及檢查是否存在任何衝突或違反約束。透過向協調者回答 “是”,節點承諾,只要請求,這個事務一定可以不出差錯地提交。換句話說,參與者放棄了中止事務的權利,但沒有實際提交。
- 當協調者收到所有準備請求的答覆時,會就提交或中止事務作出明確的決定(只有在所有參與者投贊成票的情況下才會提交)。協調者必須把這個決定寫到磁碟上的事務日誌中,如果它隨後就崩潰,恢復後也能知道自己所做的決定。這被稱為 提交點(commit point)。
- 一旦協調者的決定落盤,提交或中止請求會發送給所有參與者。如果這個請求失敗或超時,協調者必須永遠保持重試,直到成功為止。沒有回頭路:如果已經做出決定,不管需要多少次重試它都必須被執行。如果參與者在此期間崩潰,事務將在其恢復後提交 —— 由於參與者投了贊成,因此恢復後它不能拒絕提交。
sequenceDiagram
participant App as 應用
participant Coordinator as 協調者
participant Node1 as 參與者1
participant Node2 as 參與者2
App->>Coordinator: 請求事務ID
Coordinator->>App: 返回事務ID
App->>Node1: 啟動單節點事務(事務ID)
App->>Node2: 啟動單節點事務(事務ID)
Note over Node1,Node2: 執行事務中...
App->>Coordinator: 準備提交
Coordinator->>Node1: 準備請求(事務ID)
Coordinator->>Node2: 準備請求(事務ID)
Node1->>Coordinator: 是
Node2->>Coordinator: 是
Note over Coordinator: 所有參與者都已準備好
Coordinator->>Coordinator: 決定提交並記錄到事務日誌
Coordinator->>Node1: 提交請求(事務ID)
Coordinator->>Node2: 提交請求(事務ID)
Node1->>Coordinator: 提交成功
Node2->>Coordinator: 提交成功
結論:
2PC可以保證原子性的原因是”協調者追蹤決定並使其不可撤銷”
比喻:
回到西方結婚儀式
1.牧師再問雙方是否要結婚(只要其中一放放棄牧師就不可能會繼續事務)
2.其中有一個人昏倒(沒有聽到"正式宣布成為夫妻”)因為說出我願意了所以還是有效
3.當昏倒的那個人醒來,可以透過查詢牧師的預約日誌查詢是否結婚成功
協調者失效
如果任何一個準備請求超時,協調者就會終止事務。如果提交或終止請求失敗。協調者將會無條件重試。
如果再准便前請求失敗,參與者可以安全終止事務,必須等待協調者回復提交終止或是成功,一旦協調者出現網路或是崩潰問題,餐與者就只能傻傻等待。所以參與者對於這種事務狀態稱為存疑或不確定。
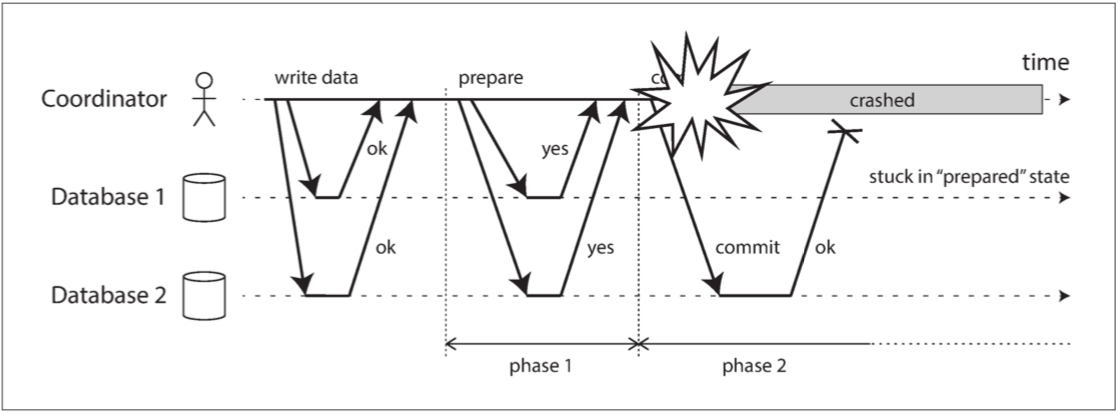
圖 9-10 參與者投贊成票後,協調者崩潰。資料庫 1 不知道是否提交或中止
這張圖說明了協調者在提交部分出現問題導致參與者1只能呆呆的等待,少了協調者的訊息參與者不會知道事務已經提交或是放棄。在這種狀況底下只能等待協調者,所以這就是為什麼參與者需要在提交或終止之前先將”我願意”寫到日誌的原因因為最後的提交還是有可能失敗,任何沒有寫在事務日誌的提交紀錄都會被終止,所以2PC的提交點就是協調者的常規單節點原子原則。
sequenceDiagram
participant Coordinator as 協調者
participant Node1 as 參與者1
participant Node2 as 參與者2
participant Log1 as 參與者1日誌
participant LogC as 協調者日誌
Coordinator->>Node1: 準備請求(事務ID)
Coordinator->>Node2: 準備請求(事務ID)
Node1->>Log1: 寫入"我願意"(事務ID)
Node2->>Coordinator: 是(事務ID)
Coordinator->>LogC: 寫入決定:提交(事務ID)
Note over Coordinator: 協調者出現問題,暫時無法通訊
Note over Node1: 等待協調者的提交/中止請求...
Note over Coordinator: 協調者恢復
Coordinator->>LogC: 讀取事務日誌(事務ID)
Coordinator->>Node1: 提交請求(事務ID)
Coordinator->>Node2: 提交請求(事務ID)
Node1->>Coordinator: 提交成功(事務ID)
Node2->>Coordinator: 提交成功(事務ID)
三階段提交
1.兩階段提交(2PC)被視為阻塞的原子提交協議,因為在協調者故障時會造成參與者的等待。
2.三階段提交(3PC)作為2PC的替代方案,但其有效性依賴於有限的網路延遲和節點響應時間,這在實際系統中不常見。
3.非阻塞原子提交需要完美的故障檢測器以可靠地判斷節點的狀態,但在無限延遲的網路中,超時不是一個可靠的故障檢測機制。
4.由於這些挑戰,2PC仍被使用,儘管存在協調者故障的可能性。
實踐中的分散式事務
介紹:
分散式事務的名聲譭譽參半,尤其是那些透過兩階段提交實現的。一方面,它被視作提供了一個難以實現的重要的安全性保證;另一方面,它們因為導致運維問題,造成效能下降,做出超過能力範圍的承諾而飽受批評。許多雲服務由於其導致的運維問題,而選擇不實現分散式事務。
報告顯示MySQL的分散事務比單節點事務慢了10倍以上,2PC不只需要使用較高的效能大部分時間都是在處理崩潰恢復所需的強制寫入(fsync)與網路往返。
fsync:
fsync 是一個在多種操作系統中使用的系統呼叫,其主要目的是確保指定的文件描述符(file descriptor)所關聯的文件的所有元數據和元信息已經從操作系統的緩衝區寫入到底層存儲系統。當一個程序寫入文件時,操作系統可能會將數據暫時保留在緩衝區中,以便稍後再將它寫入磁碟,以提高效率。然而,在某些情況下,程序可能需要確保數據已經被實際寫入磁碟,以防止在系統崩潰或其他故障情況下失去數據。
分散式事務:
1.資料庫內部的分散式事務
相同的資料庫例如 MySQL Cluster的NDB與VoltDB,所有參與事務的節點都是使用相同的資料庫軟體。
2.異構分散式事務
由兩種或是兩種以上不同技術組成,甚至是非資料庫系統(訊息代理)。跨系統的分散式事務必須要確保原子提交。
恰好一次的訊息處理
異構的分散式事務只要能提供提交原子性來視線安全提交並且保證只被處理一次,假設郵件伺服器不支援2PC,如果訊息處理失敗並重試則可能導致重複發送郵件問題,但是如果訊息都可以在事務終止回滾,那這樣處理流程就可以安全地重試而且就好像什麼錯誤都沒有發生過一樣。
XA事務
1.X/Open XA(擴充套件架構,eXtended Architecture)**是一個於1991年推出的標準,旨在通過兩階段提交實現異構技術間的整合,廣泛應用於許多傳統關聯式資料庫和訊息代理中。
2.XA非網路協議,而是一個C API,用於連線至事務協調者。它也有在其他語言例如Java中的實現,如Java事務API (JTA)。
3.事務協調者需實現XA API,通常是作為一個庫載入到發起事務的應用程序中,並使用本地磁碟上的日誌記錄事務的決定(提交/中止)。
4.如果應用程序崩潰,協調者也會失效。必須重啟伺服器並讓協調程序庫讀取日誌以恢復每個事務的提交/中止結果,然後協調者才能要求參與者提交或中止。
5.通訊必須透過客戶端庫,因為資料庫伺服器不能直接聯絡協調者。這意味著所有的事務協調都是通過應用程序進行的。
結論:
XA事務就是一種以API的形式讓許多想要整合不同系統上事務用的通用溝通介面,並保證數據的一致性與完整性。我的認知是XA事務就是多系統的協調者
假設:
- 初始化事務
- 您的應用程序首先會向事務協調者發起一個新的事務。
- 準備階段
- 應用程序將執行必要的操作,例如:
- 在MySQL中插入一條新的記錄。
- 在Redis中設置一個新的key-value對。
- 在RabbitMQ中發布一條新的訊息。
- 每個系統的操作都會通過XA API告知事務協調者它們已經準備好提交或回滾。
- 應用程序將執行必要的操作,例如:
- 提交或回滾
- 如果所有的操作都成功準備好,事務協調者會告知所有的系統提交事務。
- 如果任何一個操作報告它不能提交,或者在準備階段出現錯誤,事務協調者會告知所有的系統回滾事務。
- 結束事務
- 一旦所有的系統都報告事務已經被提交或回滾,事務協調者會結束這個事務。
sequenceDiagram
participant App as Application
participant TM as Transaction Manager
participant MySQL
participant Redis
participant RabbitMQ
App->>TM: Start Transaction
TM->>MySQL: Prepare
TM->>Redis: Prepare
TM->>RabbitMQ: Prepare
MySQL->>TM: Ready
Redis->>TM: Ready
RabbitMQ->>TM: Ready
TM->>MySQL: Commit
TM->>Redis: Commit
TM->>RabbitMQ: Commit
MySQL->>TM: Acknowledge Commit
Redis->>TM: Acknowledge Commit
RabbitMQ->>TM: Acknowledge Commit
TM->>App: Transaction Completed
這是我想像中XA事務當作協調者可能會做的事情
懷疑持有鎖
為什麼我們這麼關心存疑事務?系統的其他部分就不能繼續正常工作,無視那些終將被清理的存疑事務嗎?
1.如果其他部分如果繼續運作會導致髒寫,或是資料不一致性。
2.如果協調者崩潰,事務必須在整個存疑期間持有這個鎖,這可能導致應用大面積不可用,直到存疑事務得到解決。
3.存疑事務是問題的核心,因為它們持有資料庫的鎖,並阻止其他事務訪問相同的資料行。
結論:
回到9-9這裡存疑事務並沒有說明的很清楚但是經過查證過後應該是9-9的灰色部分locks held by transaction,在這個狀況底下所有需要使用事務的節點都會被這個鎖卡死。
sequenceDiagram
participant 協調者
participant 資料庫
participant 事務A
participant 事務B
事務A->>資料庫: 開始事務, 獲取行鎖
Note right of 資料庫: 行鎖被持有
資料庫-->>協調者: 通知事務A的行鎖
協調者->>資料庫: 保持行鎖直至提交或中止
事務B->>資料庫: 開始事務, 嘗試獲取相同行的鎖
Note right of 資料庫: 事務B被阻塞
資料庫-->>協調者: 通知事務B的阻塞
協調者-->>事務A: 請求提交或中止事務
事務A->>資料庫: 提交事務
資料庫-->>協調者: 通知事務A的提交
協調者->>資料庫: 釋放事務A的行鎖
Note right of 資料庫: 行鎖被釋放
資料庫-->>事務B: 獲取行鎖, 繼續事務
從協調者故障中恢復
理論上協調者崩潰後並重新啟動,應該可以從日誌中恢復,並解決所有的存疑事務。然而實際的系統很有可能會產生孤立的事務,孤立事務會出現在協調者無法確認事務結果的狀況發生(例如事務日誌由於軟體錯誤丟失或損壞)。當然這種狀況事務基本上無法自己解決,所以這些鎖就會卡在資料庫中阻塞其他事務。
真正的原因是因為2PC的實踐中即時重新啟動也會保留存疑事務鎖(為了保持原子性保證),唯一的方式就是讓管理者手動決定提交還是回滾,這時候管理者就要一一去查看存疑事務的參與者(昏倒的那個請他再說一次我願意,或是有點像是git的同一份文件多人修改需要人為解決衝突)。
許多XA的實踐都有一個叫做啟發式決策,允許參與者單方面決定提交或是放棄,無需協調者作出最終決定。但是壞處就是可能破壞了原子性,有趣的是啟發式代表的是可能破壞原子性的委婉說法,啟發式決策只是為了逃出災難性的情況而準備(其實發錢或是發張電影票或許可以解決)。
分散式事務的限制
XA事務解決了多個參與者相互一致的實現和重要問題,但也引入了嚴重的維運問題,事務協調者本身就是一種資料庫,因此需要像其他重要資料庫一樣小心操作。
1.如果協調者沒有HA,可能會導致存疑事務鎖死,令人驚訝的是好像很多協調者都沒有HA或者只有基本的複製支援 2.引入協調者後,間接地引入了系統狀態。通常的HTTP服務是無狀態的,但一旦加入了協調者,協調者的日誌就必須持久化以保存系統的狀態。因此,在協調者資料庫崩潰後,必須能夠恢復存疑事務。
3.由於XA協議要兼容多種不同的資料系統,它必須採用所有系統共通的基本機能。例如,XA無法檢測跨不同系統的死鎖,因為這需要一個標準的協議來交換各個事務正在等待的鎖的資訊,而XA並未提供這樣的協議。
4.相對於XA,針對資料庫內部的分散式事務,限制不是那麼嚴格。例如,可以實現分散式版本的SSI。然而,仍然存在一些問題:使用兩階段提交(2PC)成功提交一個事務需要得到所有參與者的回應。所以,如果系統的任何一部分出現故障,事務就會失敗。因此,分散式事務有放大失效(amplifying failures)的風險,這與我們構建容錯系統的目標是相違背的。
容錯共識
介紹:
共識=多個節點就某個事件達成一致
例如多個人同時嘗試定飛機最後一個位置,共識演算法可以用來確定這些互不相容的操作,最終決定哪一個是贏家
一個或多個節點可以提議某些值,而共識演算法決定採用某個值。
例如:
在訂飛機票的時候,當同時多個客戶嘗試訂購最後一個座位時,處理request的每個節點可以提議將要服務的客戶ID,而決定指明哪個客戶訂到座位
共識演算法必須滿足以下性質:
統一共識,相當於不可靠故障檢測器的非同步系統中的常規共識,學術文獻通常指的是process而不是節點。在這裡使用節點。
屬性解釋:
- 一致同意(Uniform agreement)
沒有兩個節點的決定不同。 - 完整性(Integrity)
沒有節點決定兩次。 - 有效性(Validity)
如果一個節點決定了值v,則v由某個節點所提議。 - 終止(Termination)
由所有未崩潰的節點來最終決定值。
- 共識核心屬性:
- 在共識演算法的領域中,"一致同意"(Agreement)、"完整性"(Integrity)和"有效性"(Validity)是三個基本的屬性,它們共同定義了一個良好共識演算法的基本要求。
- 一致同意(Agreement):
- 這個屬性要求所有非失效的節點必須達成共識,即它們都必須同意同一個值。所有人必須達成相同的決定。
- 完整性(Integrity):
- 完整性要求一個值一旦被選定,就不應該被改變。換句話說,每個節點只能接受一個值,並且一旦值被決定,就不能更改。
- 有效性(Validity):
- 有效性要求被選定的值必須是由某個節點提議的值,而不應是一個隨意創造的值。這個屬性主要是為了避免某些“偽”解決方案。一個演算法可能始終選擇**
null**作為共識值,無論節點們提議了什麼值。這個演算法滿足了一致同意和完整性(因為它始終選擇同一個值並且不會更改它),但它不滿足有效性,因為它選擇的值並不是由節點提議的。
- 有效性要求被選定的值必須是由某個節點提議的值,而不應是一個隨意創造的值。這個屬性主要是為了避免某些“偽”解決方案。一個演算法可能始終選擇**
這三個屬性合起來確保了共識演算法的基本要求:所有非失效的節點能夠達成共識,選定一個由節點提議的值,並且一旦這個值被選定,就不能再被更改。這是實現分布式系統一致性的基本框架,並確保了系統的穩定性和可靠性。
如果不關心容錯,那麼滿足前三個屬性很容易:你可以將一個節點硬編碼為 “獨裁者”,並讓該節點做出所有的決定。但如果該節點失效,那麼系統就無法再做出任何決定。事實上,這就是我們在兩階段提交的情況中所看到的:如果協調者失效,那麼存疑的參與者就無法決定提交還是中止。 - 獨裁者節點與協調者的影響:
- 硬編碼一個節點作為“獨裁者”可以輕易達成共識,但若該節點失效,系統不能做出決定。
- 兩階段提交的情況下,若協調者失效,存疑的參與者不能決定提交還是中止。
- 終止屬性與容錯:
- 終止屬性要求共識演算法不能無限期地等待,即使有節點失效,也必須達成決定。
- 終止屬性取決於,不超過一半節點不可用。
- 即使大多數節點失效或網路存在問題,共識的實現仍需保證安全屬性(一致同意,完整性和有效性)。
- 拜占庭錯誤((n+1)/3)與共識:
- 大多數共識演算法假設不存在拜占庭錯誤,即節點都會正確遵循協議。
- 穩健地達成共識是可能的,只要少於三分之一的節點存在拜占庭錯誤。
共識演算法和全序廣播
最著名的容錯共識演算法是檢視戳複製(VSR, Viewstamped Replication)。但是本書不介紹!!!暸解共通的高階思想就足夠了,除非自己要實現一個共識系統。
大多數的共識演算法實際上並不直接使用剛剛提到的這些模型(提議與決定單個值,並滿足一致同意、完整性、有效性和終止屬性)。取而代之的反而是值的順序,同時也促使了全序廣播演算法。
全序廣播要求將訊息按照相同的順序,恰好傳送一次,準確地送到所有節點。
所以全序廣播相當於重複進行了多輪共識(每次共識決定與一次訊息傳遞相對應):
- 由於 一致同意 屬性,所有節點決定以相同的順序傳遞相同的訊息。
- 由於 完整性 屬性,訊息不會重複。
- 由於 有效性 屬性,訊息不會被損壞,也不能憑空編造。
- 由於 終止 屬性,訊息不會丟失。
視戳複製,Raft 和 Zab 直接實現了全序廣播,因為這樣做比重複 一次一值(one value a time) 的共識更高效。在 Paxos 的情況下,這種最佳化被稱為 Multi-Paxos。
結論:
全序廣播棒棒,支持了共識演算法所需要基本要求一致同意……等等屬性
單主複製與共識
為什麼在第五章沒有擔心過共識問題?因為單主複製將所有操作都交給主庫並以相同的順序丟給從庫,使從庫的副本保持在最新狀態。
如果主庫是由維運人員手動操作那就是一種獨裁型別的共識演算法:只有一個節點被允許接受寫入,如果該節點發生故障,則整個系統無法寫入,直到維運人員處理。這樣的系統在實踐中表現良好,但是無法滿足終止屬性,因為需要人為干預才能取得進展。
某些資料庫會自動執行領導者選舉,但是會導致腦裂,因為領導者之間需要共識演算法。
結論:
要有共識演算法要先有領導者,而選出領導者TMD又要有共識演算法所以,先有雞還是先有蛋的問題出現了!
紀元編號和法定人數
- 領導者與紀元編號的關係:
- 共識協議通常內部有領導者的概念,但不能保證領導者的獨一無二。通過紀元編號(在不同協議中可能有不同名稱)來確保在每個時期,領導者是唯一的。
- 領導者選舉:
- 當現任領導者被認為失效時,節點間會開始新的領導者選舉,並賦予新的紀元編號,以保證紀元編號的全序且單調遞增。
- 領導者衝突的解決:
- 若不同時期的領導者之間出現衝突,則以紀元編號較高的領導者為准。
- 法定人數:
- 一個領導者在做出任何決定前,必須先從法定人數的節點中獲得贊成。通常需要兩輪投票:一輪選出領導者,一輪對領導者的提議進行投票。
- 投票過程與2PC的區別:
- 這個投票過程與兩階段提交(2PC)相似,但區別在於領導者的產生方式及投票要求。共識演算法只需要多數節點的贊成,並且有明確的恢復過程來保證系統的安全屬性。
結論:
在領導者選拔裡弄了一個更嚴謹的紀元編號與法定人數並讓編號最大的人當選領導者,投票過程就是更嚴謹的2PC
sequenceDiagram
participant Node1
participant Node2
participant Node3
participant Node4
Note over Node1,Node4: 初始狀態 (領導者: Node1)
alt 領導者失效
Node1->>Node1: 領導者失效
end
Note over Node1,Node4: 紀元編號 1 開始
Node2->>+Node3: 領導者失效,開始領導者選舉 (紀元編號: 1)
Node3->>+Node2: 投票給 Node2 (紀元編號: 1)
Node4->>+Node2: 投票給 Node2 (紀元編號: 1)
Note over Node2,Node4: Node2 以多數票當選為領導者
Node2->>Node3: 提議值 (紀元編號: 1)
Node2->>Node4: 提議值 (紀元編號: 1)
Node3->>Node2: 贊成提議 (紀元編號: 1)
Node4->>Node2: 贊成提議 (紀元編號: 1)
Note over Node2,Node4: 提議值被以多數票接受
alt 領導者失效
Node2->>Node2: 領導者失效
end
Note over Node2,Node4: 紀元編號 2 開始
alt Node1恢復
Node1->>Node1: Node1恢復
end
Node1->>+Node3: 領導者失效,開始領導者選舉 (紀元編號: 2)
Node3->>+Node1: 投票給 Node1 (紀元編號: 2)
Node4->>+Node1: 投票給 Node1 (紀元編號: 2)
Note over Node1,Node4: Node1 以多數票當選為領導者
Node1->>Node3: 提議值 (紀元編號: 2)
Node1->>Node4: 提議值 (紀元編號: 2)
Node3->>Node1: 贊成提議 (紀元編號: 2)
Node4->>Node1: 贊成提議 (紀元編號: 2)
Note over Node1,Node4: 提議值被以多數票接受
alt Node2恢復
Node2->>Node2: Node2恢復
end
alt 領導者衝突的解決
Node2->>Node1: 嘗試成為領導者 (紀元編號: 2)
Node1->>Node2: 以更高的紀元編號解決衝突 (紀元編號: 3)
end
Note over Node1,Node4: Node1 保持為領導者
- 初始狀態:
- 系統初始時,Node1 是領導者。
- 領導者失效 (Node1):
- Node1 失效,系統進入紀元編號1。
- 領導者選舉 (紀元編號 1):
- Node2、Node3 和 Node4 開始領導者選舉。Node3 和 Node4 投票給 Node2,Node2 以多數票當選為新的領導者。
- 提議和投票 (紀元編號 1):
- Node2 提出一個提議值,並得到 Node3 和 Node4 的贊成,提議值被多數票接受。
- 領導者失效 (Node2):
- Node2 失效,系統進入紀元編號2。
- Node1恢復:
- Node1 恢復並參與接下來的領導者選舉。
- 領導者選舉 (紀元編號 2):
- Node1、Node3 和 Node4 開始領導者選舉。Node3 和 Node4 投票給 Node1,Node1 以多數票當選為新的領導者。
- 提議和投票 (紀元編號 2):
- Node1 提出一個提議值,並得到 Node3 和 Node4 的贊成,提議值被多數票接受。
- Node2恢復:
- Node2 恢復並嘗試重新成為領導者。
- 領導者衝突的解決:
- Node2 嘗試在紀元編號2成為領導者,但 Node1 以更高的紀元編號(3)回應,以解決領導者衝突,並保持為領導者。
共識的局限性
共識演算法為分散式系統提供了基本的安全屬性,如一致同意、完整性和有效性,並在多數節點正常運作時保持容錯和進展。但它有其侷限性:
- 同步複製問題:共識演算法依賴同步複製來確保一致性,與常見的非同步複製相比,可能會在效能上有所損失。
- 節點數量要求:至少需要三個節點以容忍單節點故障,五個節點以容忍兩個節點故障。如果網路故障導致節點間連線中斷,只有多數節點所在的網路能繼續運作。
- 固定節點集合:多數共識演算法假設參與投票的節點是固定的,雖然有動態成員擴充套件,但理解和實施較為困難。
- 超時檢測的依賴:共識系統依賴超時來檢測失效節點,但在網路延遲高度變化的環境中可能會導致錯誤的失效檢測和領導者選舉,影響效能。
- 對網路問題的敏感性:例如,Raft 在特定的網路連線不可靠時可能會出現領導者頻繁切換的問題,影響系統進展。這類問題在其他一致性演算法中也存在,而設計能夠健壯應對不可靠網路的演算法仍是開放的研究領域。
Raft:
Raft是一種用於替代Paxos的共識演算法。相比於Paxos,Raft的目標是提供更清晰的邏輯分工使得演算法本身能被更好地理解,同時它安全性更高,並能提供一些額外的特性。[1][2]:1Raft能為在電腦叢集之間部署有限狀態機提供一種通用方法,並確保叢集內的任意節點在某種狀態轉換上保持一致。Raft演算法的開源實現眾多,在Go、C++、Java以及 Scala中都有完整的代碼實現。Raft這一名字來源於"Reliable, Replicated, Redundant, And Fault-Tolerant"(「可靠、可複製、可冗餘、可容錯」)的首字母縮寫。[3]
叢集內的節點都對選舉出的領袖採取信任,因此Raft不是一種拜占庭容錯演算法。[2]
拜占庭將軍問題:
一組拜占庭將軍分別各率領一支軍隊共同圍困一座城市。為了簡化問題,將各支軍隊的行動策略限定為進攻或撤離兩種。因為部分軍隊進攻部分軍隊撤離可能會造成災難性後果,因此各位將軍必須通過投票來達成一致策略,即所有軍隊一起進攻或所有軍隊一起撤離。因為各位將軍分處城市不同方向,他們只能通過信使互相聯絡。在投票過程中每位將軍都將自己投票給進攻還是撤退的資訊通過信使分別通知其他所有將軍,這樣一來每位將軍根據自己的投票和其他所有將軍送來的資訊就可以知道共同的投票結果而決定行動策略。
成員與協調服務
介紹:
ZooKeeper 和 etcd 被設計為容納少量完全可以放在記憶體中的資料(雖然它們仍然會寫入磁碟以保證永續性),所以你不會想著把所有應用資料放到這裡。這些少量資料會透過容錯的全序廣播演算法複製到所有節點上。正如前面所討論的那樣,資料庫複製需要的就是全序廣播:如果每條訊息代表對資料庫的寫入,則以相同的順序應用相同的寫入操作可以使副本之間保持一致。
- 線性一致性的原子操作
使用原子 CAS 操作可以實現鎖:如果多個節點同時嘗試執行相同的操作,只有一個節點會成功。共識協議保證了操作的原子性和線性一致性,即使節點發生故障或網路在任意時刻中斷。分散式鎖通常以 租約(lease) 的形式實現,租約有一個到期時間,以便在客戶端失效的情況下最終能被釋放(請參閱 “程序暫停”)。 - 操作的全序排序
如 “領導者和鎖” 中所述,當某個資源受到鎖或租約的保護時,你需要一個防護令牌來防止客戶端在程序暫停的情況下彼此衝突。防護令牌是每次鎖被獲取時單調增加的數字。ZooKeeper 透過全序化所有操作來提供這個功能,它為每個操作提供一個單調遞增的事務 ID(zxid)和版本號(cversion)【15】。 - 失效檢測
客戶端在 ZooKeeper 伺服器上維護一個長期會話,客戶端和伺服器週期性地交換心跳包來檢查節點是否還活著。即使連線暫時中斷,或者 ZooKeeper 節點失效,會話仍保持在活躍狀態。但如果心跳停止的持續時間超出會話超時,ZooKeeper 會宣告該會話已死亡。當會話超時時(ZooKeeper 稱這些節點為 臨時節點,即 ephemeral nodes),會話持有的任何鎖都可以配置為自動釋放。 - 變更通知
客戶端不僅可以讀取其他客戶端建立的鎖和值,還可以監聽它們的變更。因此,客戶端可以知道另一個客戶端何時加入叢集(基於新客戶端寫入 ZooKeeper 的值),或發生故障(因其會話超時,而其臨時節點消失)。透過訂閱通知,客戶端不用再透過頻繁輪詢的方式來找出變更。
在這些功能中,只有線性一致的原子操作才真的需要共識。但正是這些功能的組合,使得像 ZooKeeper 這樣的系統在分散式協調中非常有用。
結論:
在使用分散式資料庫時其實要考慮哪些資訊是必須線性一致性的,如果需要線性一致性的資料再放入像是ZooKeeper這種分散式資料庫保證線性一致性的原子操作。或是說如果是最終一致性的內容就不需要放到這種分散式資料庫的架構讓node之間彼此慢慢溝通就好了。
將工作分配給節點
ZooKeeper/Chubby 模型執行良好的一個例子是,如果你有幾個程序例項或服務,需要選擇其中一個例項作為主庫或首選服務。如果領導者失敗,其他節點之一應該接管。這對單主資料庫當然非常實用,但對作業排程程式和類似的有狀態系統也很好用。
- 領導者選舉與失敗恢復:
- ZooKeeper或Chubby模型可以用於選擇主節點或首選服務,並在主節點失效時由其他節點接管,這在單主資料庫、作業排程系統和其他有狀態系統中非常實用。
- 資源分割槽的分配與再平衡:
- 通過使用ZooKeeper,可以決定將哪個分割槽分配給哪個節點,並在新節點加入或節點失效時重新平衡負載。
- 原子操作、臨時節點與通知:
- ZooKeeper提供了原子操作、臨時節點和通知功能,有助於實現分割槽的再平衡和失效節點的工作接管,並能讓系統自動從故障中恢復。
- 高層工具的支援:
- 例如Apache Curator,它是基於ZooKeeper客戶端API而提供更高層的工具,降低了從頭實現共識演算法的困難和風險。
- 協調節點的外包:
- ZooKeeper允許在固定數量的節點上執行多數票選舉,而非在數千個節點上,並“外包”一些協調節點的工作,如共識、操作排序和故障檢測,以支援大量的客戶端。
- 資料型別的緩慢變化:
- ZooKeeper適合管理變化緩慢的資料,而不是每秒會改變數千或數百萬次的執行時狀態資料。
- 其他工具的配合:
- 如Apache BookKeeper,可以用於複製應用狀態,與ZooKeeper配合使用,提供更完整的分散式系統解決方案。
結論:
各種工具特性與應用方式
服務發現
- 服務發現:
- ZooKeeper、etcd 和 Consul 常用於服務發現,即確定連接到特定服務所需的 IP 地址。在雲資料中心,由於虛擬機器的動態性,服務的 IP 地址通常不是事先知道的。服務可配置為在啟動時註冊其網路端點,以便其他服務能夠找到它們。
- 共識與服務發現:
- 服務發現不一定需要共識,而是更重視可用性和對網路中斷的魯棒性。傳統上,DNS 用於查詢服務的 IP 地址,並通過多層快取來提高效能和可用性,它不保證線性一致性。
- 領導者選舉:
- 與服務發現不同,領導者選舉需要共識。如果共識系統已經識別出領導者,這些資訊可以用於幫助其他服務找出領導者。
- 只讀快取副本:
- 一些共識系統支援只讀快取副本,這些副本能非同步接收共識演算法的所有決策日誌,但不參與投票,從而能夠處理不需要線性一致性的讀取請求,降低了需求共識的情境,同時保持了系統的效能與可用性。
成員資格服務
- 成員資格服務的核心功能:
- 它主要用於確定哪些節點目前是活動的,並且是叢集的活動成員。由於無限的網路延遲,無法可靠地檢測到另一個節點是否失效,但通過共識,節點可以達成一致意見,決定哪些節點應被認為是存在或不存在。
- 共識在故障檢測中的角色:
- 透過共識來進行故障檢測可以協助節點就哪些節點是存在或不存在達成一致。雖然可能會有節點被錯誤地宣告死亡,但對系統來說,知道哪些節點是當前的成員是非常有用的。
- 領導者選舉與成員資格:
- 在選擇領導者時,例如可能簡單地選擇當前成員中編號最小的成員。但如果不同的節點對現有成員有不同的意見,這種方法將不起作用。成員資格服務確保節點對叢集的現有成員有一致的理解,從而促進了有效的領導者選舉。
9.5 本章小結
達成共識意味著以這樣一種方式決定某件事:所有節點一致同意所做決定,且這一決定不可撤銷。透過深入挖掘,結果我們發現很廣泛的一系列問題實際上都可以歸結為共識問題,並且彼此等價(從這個意義上來講,如果你有其中之一的解決方案,就可以輕易將它轉換為其他問題的解決方案)。這些等價的問題包括:
- 線性一致性的 CAS 暫存器
暫存器需要基於當前值是否等於操作給出的引數,原子地 決定 是否設定新值。 - 原子事務提交
資料庫必須 決定 是否提交或中止分散式事務。 - 全序廣播
訊息系統必須 決定 傳遞訊息的順序。 - 鎖和租約
當幾個客戶端爭搶鎖或租約時,由鎖來 決定 哪個客戶端成功獲得鎖。 - 成員 / 協調服務
給定某種故障檢測器(例如超時),系統必須 決定 哪些節點活著,哪些節點因為會話超時需要被宣告死亡。 - 唯一性約束
當多個事務同時嘗試使用相同的鍵建立衝突記錄時,約束必須 決定 哪一個被允許,哪些因為違反約束而失敗。
如果領導者失效,或者如果網路中斷導致領導者不可達,這樣的系統就無法取得任何進展。應對這種情況可以有三種方法:
- 等待領導者恢復,接受系統將在這段時間阻塞的事實。許多 XA/JTA 事務協調者選擇這個選項。這種方法並不能完全達成共識,因為它不能滿足 終止 屬性的要求:如果領導者續命失敗,系統可能會永久阻塞。
- 人工故障切換,讓人類選擇一個新的領導者節點,並重新配置系統使之生效,許多關係型資料庫都採用這種方方式。這是一種來自 “天意” 的共識 —— 由計算機系統之外的運維人員做出決定。故障切換的速度受到人類行動速度的限制,通常要比計算機慢(得多)。
- 使用演算法自動選擇一個新的領導者。這種方法需要一種共識演算法,使用成熟的演算法來正確處理惡劣的網路條件是明智之舉【107】。