字數總計:0 個 | 閱讀時長:0 分鐘 |閱讀次數: 次
什麼是網路爬蟲?
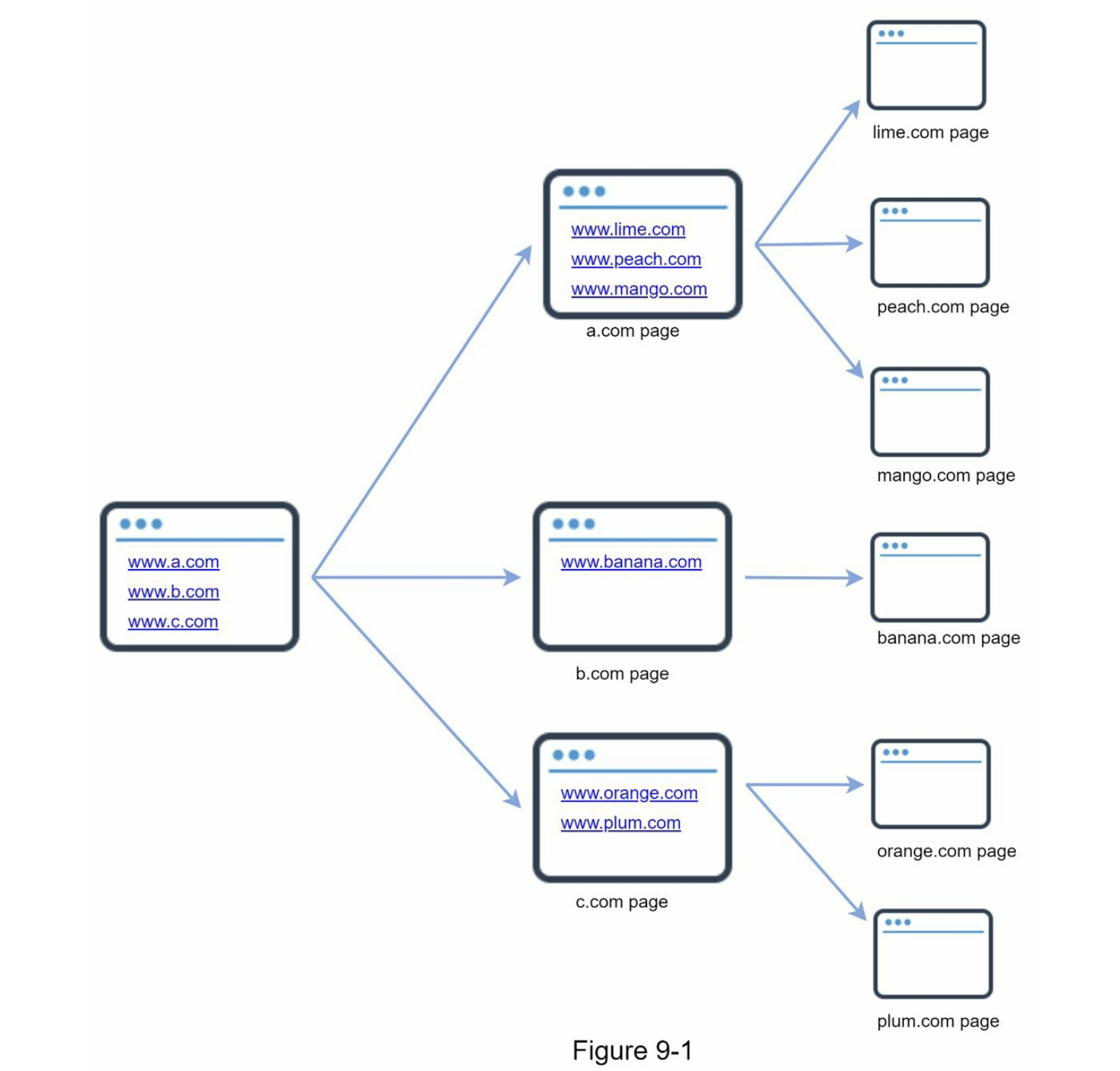
網路爬蟲,又稱 Spider 或 Robot,是一種自動化程式,用來在網際網路上 下載網頁內容、解析其中的連結,再把新連結加入待抓佇列,如此反覆迴圈地遍歷整個網站或更大的網址空間。
常見四大用途
| 用途 | 說明 | 代表例子 |
|---|---|---|
| 搜尋引擎索引 | 下載網頁並 建立 本地索引,供搜尋引擎快速查詢 | Googlebot(Google 搜尋) |
| 網路封存 (Web Archiving) | 定期擷取網站內容並長期保存,作為數位典藏 | 美國國會圖書館、歐盟網路檔案館 |
| 網路挖掘 (Web Mining) | 大規模收集公開資料,再進行資料探勘以擷取知識 | 金融機構抓取股東會與年度報告 |
| 網路監控 (Web Monitoring) | 監測版權、商標或內容侵權,偵測並通報不當使用 | Digimarc 掃描網路盜版作品 |
第一步驟:瞭解問題並確立設計的範圍
網路爬蟲基本的演算法其實很簡單:
- 給定一組網址, 然後把網址所對應的網頁全部下載下來
- 從這些網頁中提取所有的網址連結
- 把新的網址添加到所要下載的網址列表中. 重複執行以上這3個步驟.
問題釐清對話
應試者:爬蟲的主要目的是什麼?是搜尋引擎索引、資料挖掘,還是其他用途?
面試官:搜尋引擎索引。
應試者:網路爬蟲每個月需要抓取多少網頁?
面試官:10 億頁。
應試者:包含哪些內容類型?只有 HTML 嗎,還是也要處理 PDF、圖片?
面試官:只有 HTML。
應試者:是否需要偵測新增或已編輯的網頁?
面試官:是,需要考慮新增加或已修改的頁面。
應試者:抓取到的 HTML 需要保存多久?
面試官:保存最多 5 年。
應試者:如果遇到重複內容的頁面要怎麼辦?
面試官:重複內容應該忽略,不儲存。
✔︎ 以上對話用來釐清需求並確認假設,避免與面試官對「爬蟲的範圍與目標」產生落差。
優秀網路爬蟲的特徵
- 可伸縮性(Scalability)
- 網路規模極大,擁有數十億個網頁。
- 系統需支援 分散式與並行化 的抓取方式,以提升效率。
- 穩健性(Robustness)
- 網路充滿陷阱:錯誤的 HTML、無回應的伺服器、崩潰或惡意連結等。
- 爬蟲必須具備容錯機制來應對這些異常情況。
- 禮貌性(Politeness)
- 不應在短時間內對同一網站發出過多請求。
- 應遵守
robots.txt規範並設定抓取延遲,避免造成伺服器負擔。
- 可擴展性(Extensibility)
- 系統設計應保持彈性,只需少量修改即可支援新的內容型態。
- 例如:未來若要抓取圖片檔案,不需重新設計整個架構。
基本需求與核心功能
- 網頁抓取:
- 依「種子 URL → 下載 → 解析 → 新 URL 入佇列」的迴圈流程遞迴抓取。
- 更新偵測:
- 能定期重新抓取已存在的頁面,以納入新增或已編輯的內容。
- 重複內容去除:
- 以內容雜湊(content hash)或 URL 去重機制,避免存儲同樣頁面。
- 資料儲存:
- 將 HTML 存放 最長 5 年,支援高吞吐量讀寫。
粗略的估算
| 項目 | 計算 | 結果 |
|---|---|---|
| 平均 QPS | 10 億頁 ÷ 30 天 ÷ 24 小時 ÷ 3600 秒 | ≈ 400 頁/秒 |
| 峰值 QPS | 2 × 平均 QPS(假設尖峰為兩倍) | ≈ 800 頁/秒 |
| 月儲存量 | 10 億頁 × 500 KB/頁 | ≈ 500 TB/月 |
| 五年儲存量 | 500 TB/月 × 12 月 × 5 年 | ≈ 30 PB |
【補充】實際值會依抓取頻率、壓縮率與去重效率略有差異;估算時應與面試官確認每一步的假設。
第二步驟:提出高階設計並取得認可
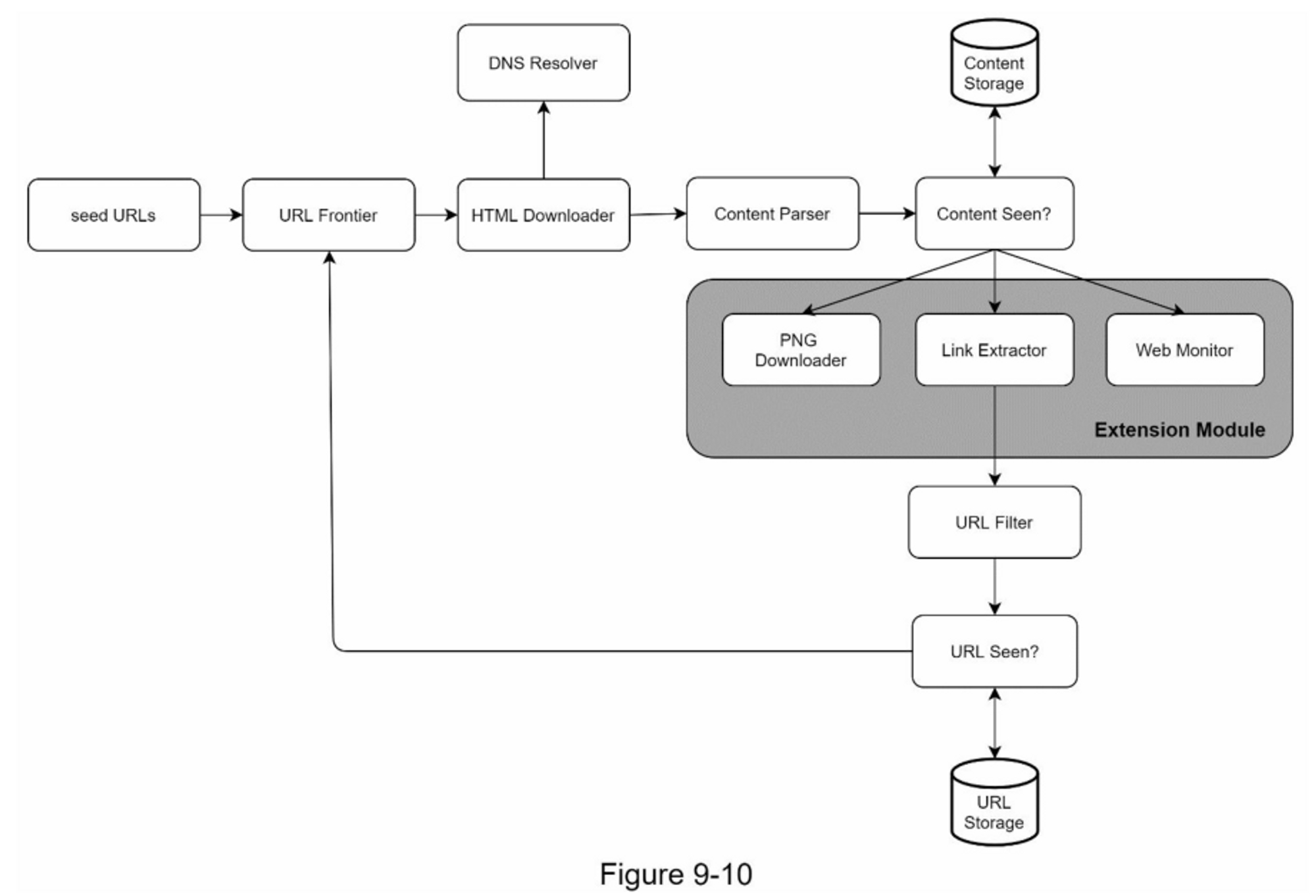
網路爬蟲的高層設計包含多個協同工作的組件,以下詳細說明各組件的功能與職責。
核心組件
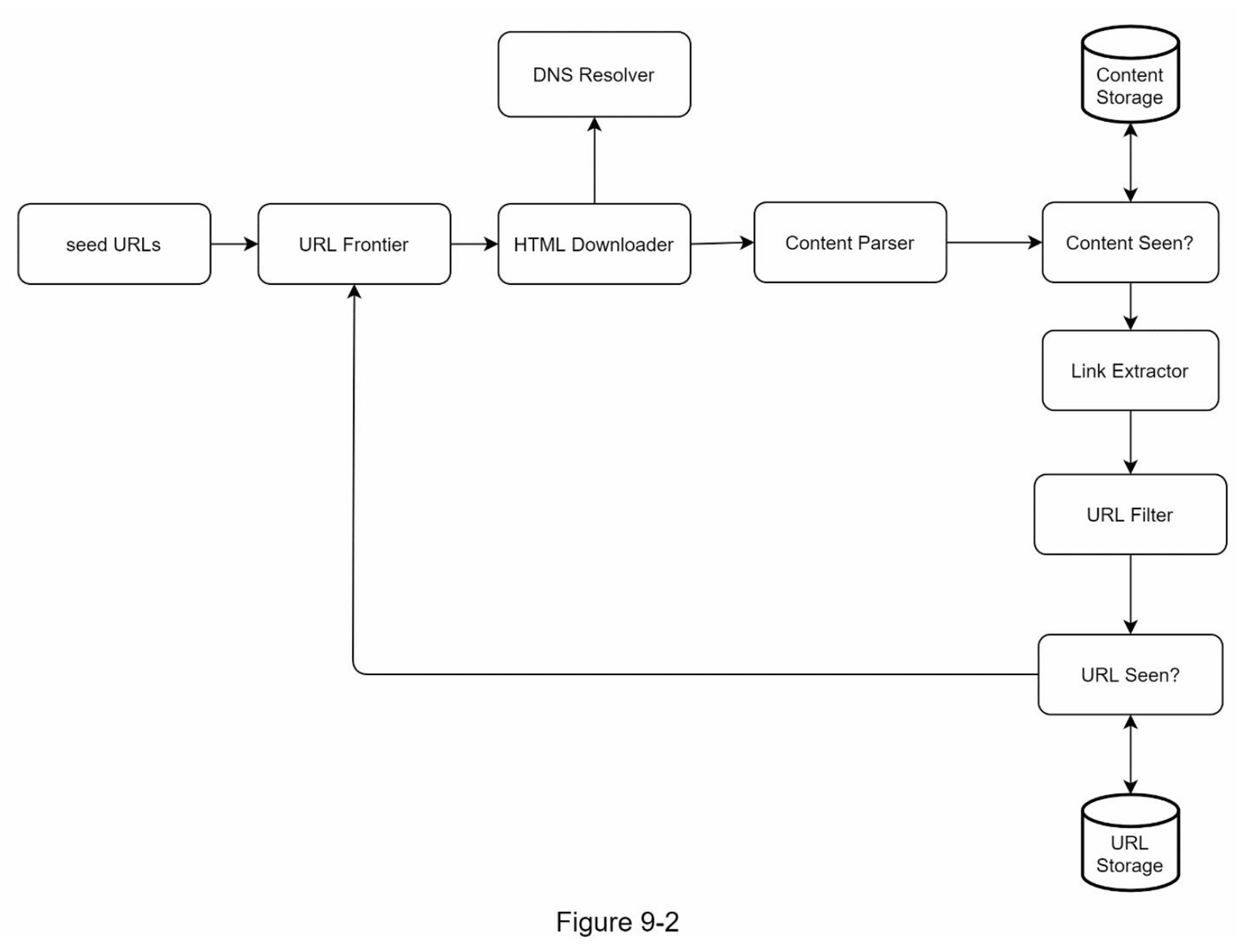
- 種子網址(Seed URLs)
- 功能:作為爬蟲的起始點
- 選擇策略:
- 單一網站:使用該網站的域名作為種子
- 全網爬取:需要創意性的選擇方法
- 基於地理位置劃分(不同國家的熱門網站)
- 基於主題劃分(購物、體育、醫療等)
- 重點:好的種子URL能讓爬蟲遍歷最多的鏈接
- 網址邊境(URL Frontier)
- 功能:儲存待下載的URL隊列
- 實作方式:FIFO(先進先出)隊列
- 狀態管理:將爬蟲狀態分為「待下載」和「已下載」
- HTML 下載器(HTML Downloader)
- 功能:從網路下載網頁內容
- 資料來源:從網址邊境(URL Frontier)獲取待下載的URL
- DNS解析器(DNS Resolver)
- 功能:將URL轉換為IP地址
- 範例:www.wikipedia.org → 198.35.26.96
- 內容解析器(Content Parser)
- 功能:解析和驗證下載的網頁
- 設計考量:
- 獨立組件設計,避免拖慢爬蟲速度
- 過濾格式錯誤的網頁,節省儲存空間
- 看過的內容(Content Seen)
- 功能:檢測重複內容(研究顯示29%的網頁是重複的)
- 實作方式:使用哈希值比較,而非逐字比較
- 效益:
- 消除數據冗余
- 縮短處理時間
- 內容儲存(Content Storage)
- 儲存策略:
- 磁碟:儲存大部分內容(數據量太大無法全部放入記憶體)
- 記憶體:快取熱門內容以降低延遲
- 選擇依據:數據類型、大小、訪問頻率、生命週期
- 網址鏈結提取器(URL/Links Extractor)
- 功能:從HTML頁面解析並提取鏈接
- 處理:將相對路徑轉換為絕對URL

範例:"/wiki/..." → "https://en.wikipedia.org/wiki/..."
- 網址篩選器(URL Filter)
- 功能:過濾不需要的URL
- 過濾條件:
- 特定內容類型
- 文件擴展名
- 錯誤Link
- 黑名單網站
- 看過的網址(URL Seen)
- 功能:追蹤已訪問過或已在Frontier中的URL
- 重要性:
- 避免重複添加相同URL
- 防止服務器過載
- 避免無限循環
實作技術:布隆過濾器(Bloom Filter)或哈希表
- 網址儲存系統(URL Storage)
- 功能:儲存已訪問過的URL記錄
- 網路爬蟲的工作流程
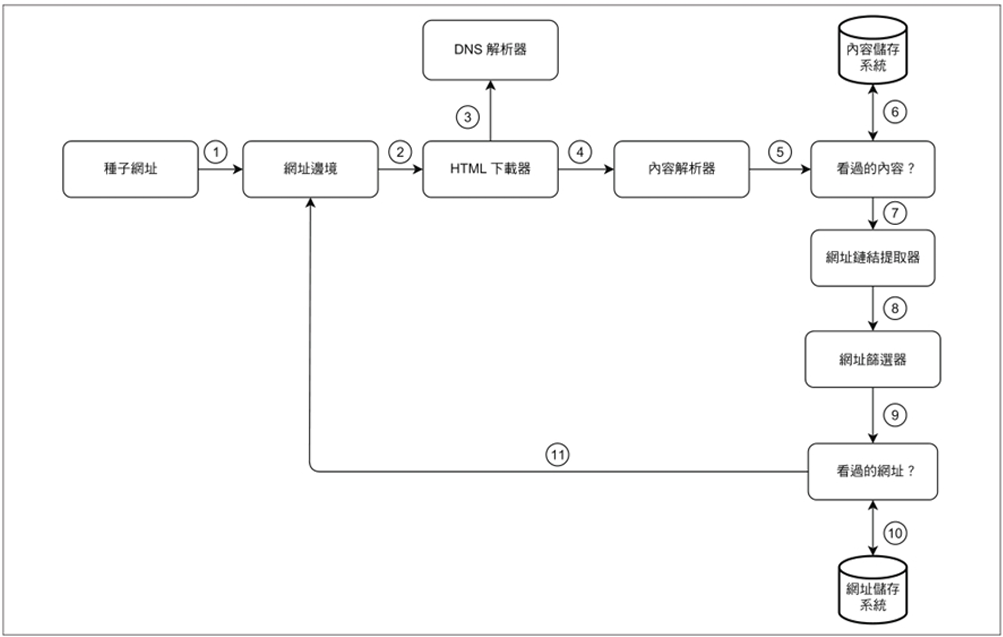
- 第 1 步:種子URL初始化, 將種子URL添加到URL Frontier隊列中,作為爬蟲的起始點。
- 第 2 步:獲取待處理URL, HTML下載器從URL Frontier獲取URL列表,準備進行下載。
- 第 3 步:解析與下載, HTML下載器透過DNS解析器獲取URL對應的IP地址,並開始下載網頁內容。
- 第 4 步:內容解析, Content Parser解析HTML頁面,檢查頁面格式是否正確,過濾掉格式錯誤的頁面。
- 第 5 步:傳遞已解析內容, 內容經過解析和驗證後,傳遞給「Content Seen?」組件進行去重檢查。
- 第 6 步:內容去重檢查「Content Seen?」組件檢查HTML頁面是否已存在於儲存系統中:
- 若已存在:表示相同內容已被處理過(可能來自不同URL),直接丟棄該HTML頁面
- 若不存在:表示是新內容,將內容傳遞給URL提取器繼續處理
- 第 7 步:提取鏈接, URL提取器從HTML頁面中解析並提取所有URL鏈接。
- 第 8 步:URL過濾, 將提取的URL傳遞給URL過濾器,過濾掉不需要的鏈接。
- 第 9 步:傳遞已過濾URL, URL過濾完成後,傳遞給「URL Seen?」組件。
- 第 10 步:URL去重檢查, 「URL Seen?」組件檢查URL是否已在儲存系統中:
- 若已存在:表示該URL已被處理過,無需採取任何行動
- 若不存在:進入下一步
- 第 11 步:加入待處理隊列, 如果URL之前沒有被處理過,將其添加到URL Frontier,等待下一輪處理。
第三步驟:深入設計
圖遍歷策略:DFS vs BFS
為何選擇BFS而非DFS
- 網路結構:網路可視為有向圖(網頁為節點,超鏈接為邊)
- DFS問題:深度可能過深,容易陷入單一網站
- BFS優勢:廣度優先,能更均勻地爬取不同網站
標準BFS的兩大問題
- 禮貌性問題:同一網頁的大部分鏈接指向同一主機,可能造成服務器請求氾濫
- 優先級問題:未考慮URL的重要性差異
💡 BFS與DFS的差異, 可以參考 BFS vs DFS
URL Frontier 詳細設計
- 禮貌性機制(Politeness)
核心原則:
- 避免短時間內向同一服務器發送過多請求
- 一次只從同一主機下載一個頁面
- 下載任務之間添加延遲
實現架構:
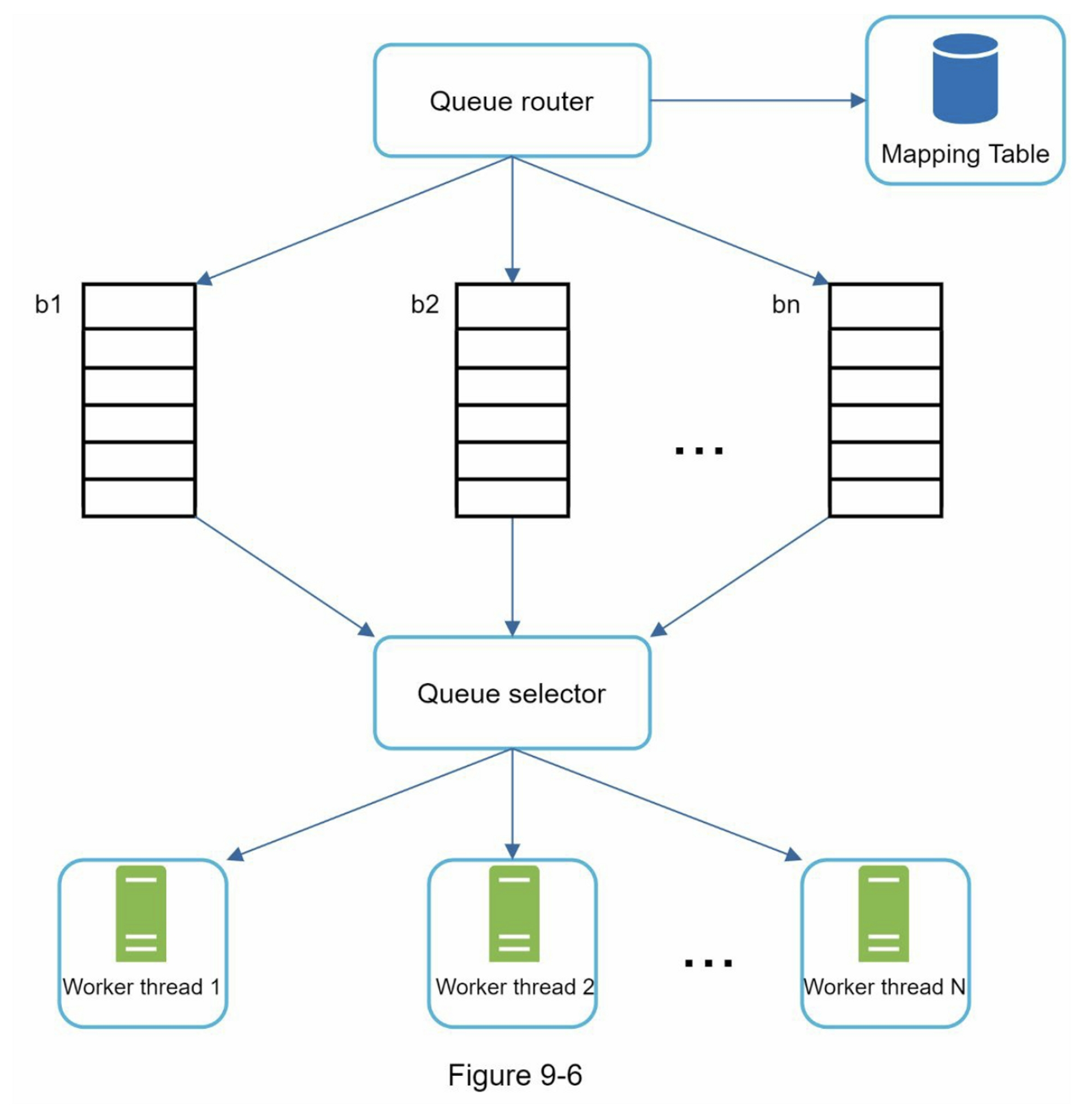
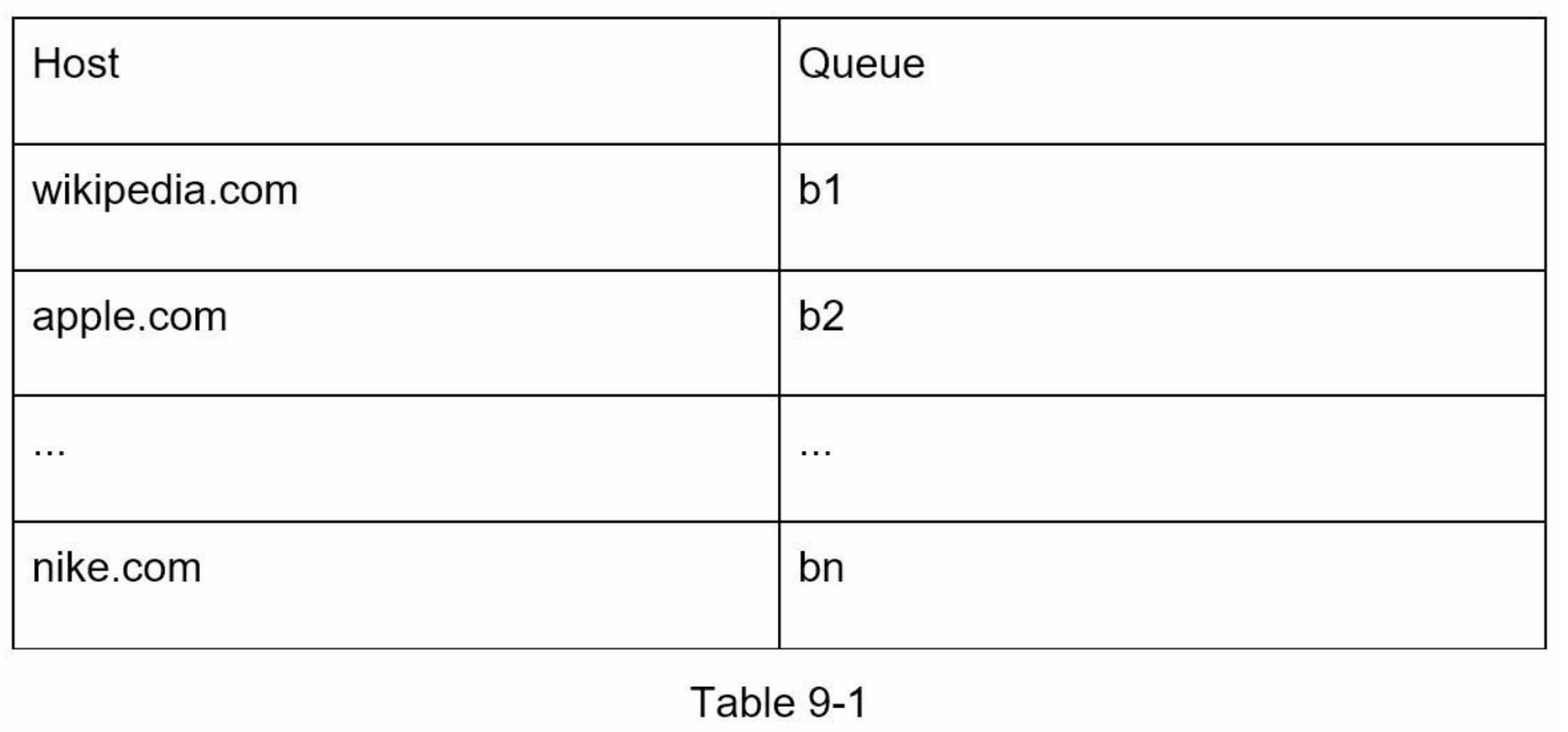
- Queue router:確保每個隊列只包含同一主機的URL
- Mapping table:主機名到隊列的映射表
- FIFO隊列(b1-bn):每個隊列對應一個主機
- Queue selector:分配工作線程到特定隊列
- Worker threads:依序下載,避免並發請求同一主機
- 優先級管理(Priority)
優先級依據:
- PageRank分數
- 網站流量
- 更新頻率
- 內容重要性
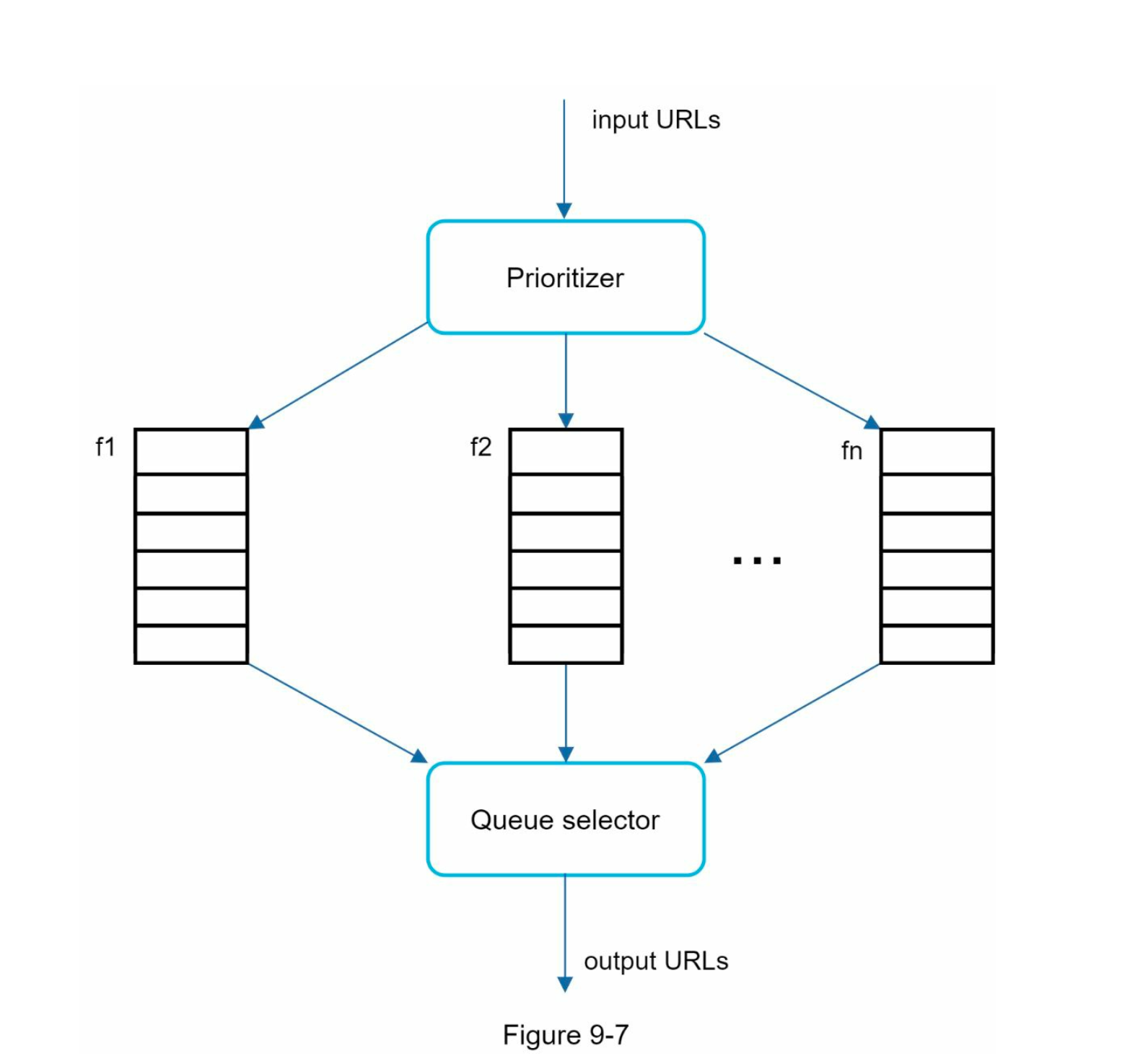
實現組件:
- Prioritizer:計算URL優先級
- 優先級隊列(f1-fn):不同優先級的隊列
- Queue selector:偏向選擇高優先級隊列
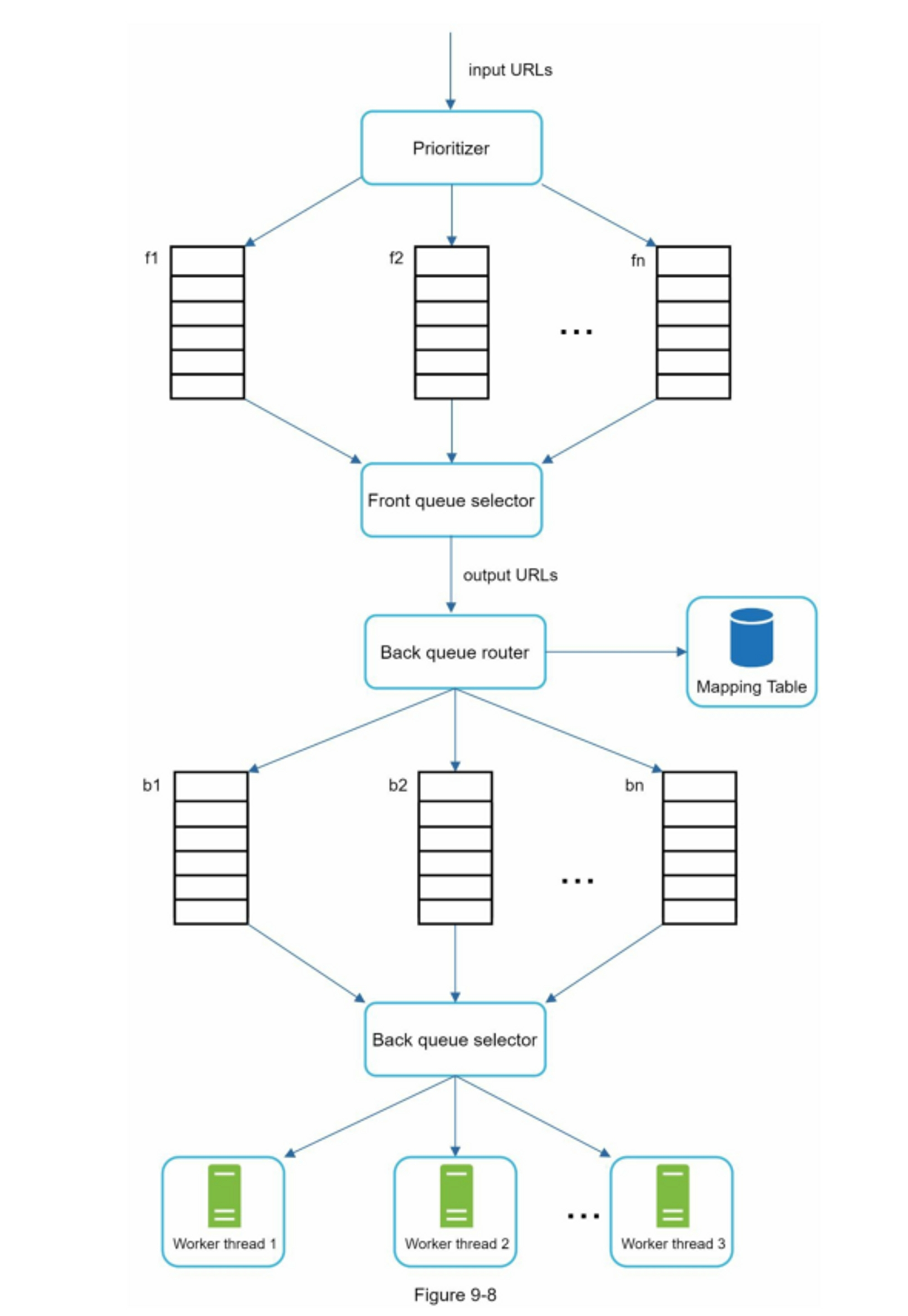
- 完整架構
- 前端隊列:管理優先級
- 後端隊列:管理禮貌性
- 新鮮度維護(Freshness)
優化策略:
- 基於歷史更新頻率調整重爬頻率
- 優先重爬重要頁面
- 動態調整爬取週期
- 儲存優化
混合儲存方案:
- 磁盤:儲存大部分URL(數億級別)
- 記憶體緩衝:加速入隊/出隊操作
- 定期同步:緩衝區數據定期寫入磁盤
HTML下載器優化
- Robots.txt協議
- 功能:網站與爬蟲的溝通標準
- 實施:
- 爬取前檢查robots.txt
- 快取結果避免重複下載
- 定期更新快取
下面是取自 https://www.amazon.com/robots.txt 的robots.txt文件
User-agent: Googlebot
Disallow: /creatorhub/*
Disallow: /rss/people/*/reviews
Disallow: /gp/pdp/rss/*/reviews
Disallow: /gp/cdp/member-reviews/
Disallow: /gp/aw/cr/
- 性能優化技術分布式爬取
- URL空間分割
- 多服務器並行處理
- 每個下載器負責特定URL子集
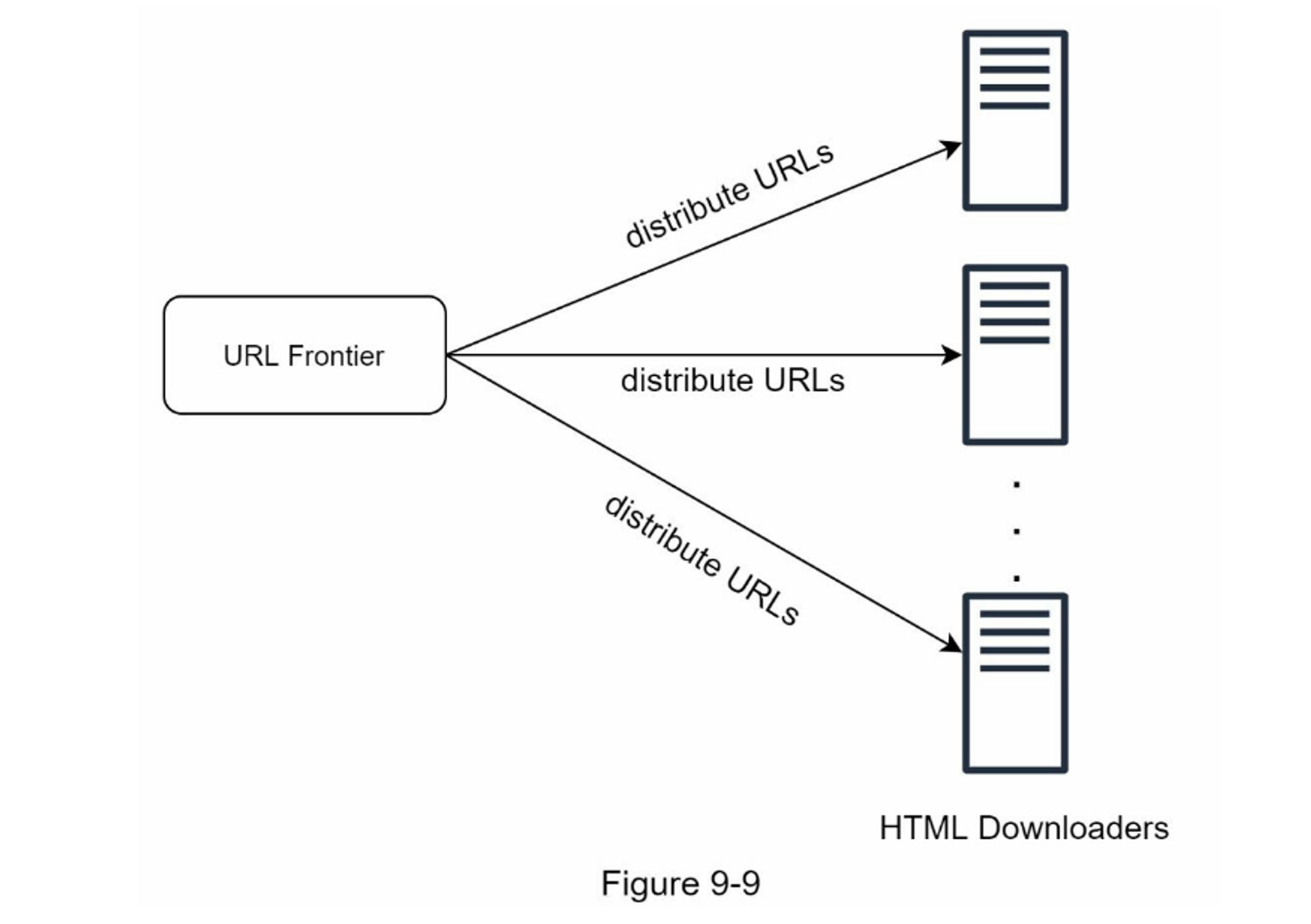
DNS優化
- 問題:DNS解析延遲(10-200ms)
- 解決方案:
- 維護DNS快取
- 域名到IP的映射表
- 定期更新(cron job)
地理位置優化
- 爬蟲服務器地理分布
- 就近爬取降低延遲
- 適用於所有系統組件
超時控制
- 設置最大等待時間
- 避免無響應服務器阻塞
- 快速切換到其他任務
系統穩健性(Robustness)
關鍵技術
- 一致性哈希:動態負載均衡,支持服務器增減
- 狀態持久化:定期保存爬取狀態,支持故障恢復
- 異常處理:優雅處理錯誤,防止系統崩潰
- 數據校驗:確保數據完整性和正確性
可擴展性(Extensibility)
插件化架構
- 模組化設計:支持動態添加新功能
- 範例擴展:
- PNG下載器模組
- 網路監控模組(版權保護)
- 其他文件類型處理器
問題內容檢測與預防
- 重複內容
- 統計:約30%網頁重複
- 解決方案:哈希值或校驗和檢測
- 蜘蛛陷阱(Spider Traps)
- 定義:導致無限循環的網頁結構
- 預防措施:
- 設置URL最大長度
- 監控單一網站頁面數異常
- 手動識別並排除
- 自定義URL過濾器
- 垃圾數據
- 類型:廣告、代碼片段、垃圾URL
- 處理:識別並排除無價值內容
關鍵要點總結
- BFS優於DFS:適合網路爬蟲的廣度遍歷
- 禮貌性至關重要:避免對服務器造成負擔
- 優先級管理:提高爬取效率和質量
- 混合儲存:平衡性能與成本
- 分布式架構:提升系統擴展性
- 多層優化:DNS、地理位置、超時控制
- 容錯設計:確保系統穩定運行
- 插件化擴展:適應未來需求變化
第四步驟:彙整總結
優秀爬蟲的四大特徵
- 可伸縮性(Scalability):能夠處理大規模網路爬取
- 禮貌性(Politeness):尊重網站服務器,避免造成負擔
- 可擴展性(Extensibility):易於添加新功能和模組
- 穩健性(Robustness):能夠處理各種異常情況
未涵蓋的重要議題
- 服務器端渲染(動態渲染)
- 問題:許多網站使用JavaScript、AJAX等腳本即時生成鏈接
- 挑戰:直接下載解析網頁無法獲取動態生成的鏈接
- 解決方案:在解析網頁前進行服務器端渲染
- 過濾不需要的頁面
- 原因:儲存容量和爬取資源有限
- 方法:使用反垃圾信息組件
- 目標:過濾低質量和垃圾頁面
- 數據庫複製和分片
- 目的:提高數據層的:
- 可用性
- 可擴展性
- 可靠性
- 水平擴展
- 規模:大規模爬取需要數百甚至數千台服務器
- 關鍵:保持服務器無狀態
- 系統核心概念
- 可用性(Availability)
- 一致性(Consistency)
- 可靠性(Reliability) 這些是任何大型系統成功的核心要素
- 分析(Analytics)
- 重要性:任何系統的重要組成部分
- 用途:數據是系統微調的關鍵要素
- 內容:收集和分析系統運行數據
關鍵要點
建置可擴展的網路爬蟲並非簡單任務,因為:
- 網路規模極其龐大
- 存在各種陷阱和挑戰
- 需要考慮多個複雜的技術層面