第1步:了解問題並確立設計的範圍
為了釐清狀況而提出問題,是解決任何系統設計面試問題的第一步。這裡有一些應試者與面試官互動的例子:
應試者:唯一 ID 的特性是什麼?
面試官:ID 必須是唯一而不可重複,而且可進行排序。
應試者:針對每一個新記錄,ID 都要增加1嗎?
面試官:ID 要隨時間遞增,但不一定只遞增1。晚上所建立的ID,必須大於當天早上所建立的ID。
應試者:ID的值只能包含數值嗎?
面試官:是的,沒錯。
應試者:ID 的長度有什麼要求?
面試官:ID 應該為 64位元。
應試者:系統的規模有多大?
面試官:系統應該要能夠每秒生成10000個ID。
以上就是一些你可以詢問面試官的問題範例。重要的是一定要瞭解要求,並釐清所有不清楚的部分。針對這個面試問題,相應的要求列表如下:
- ID 必须是唯一而不重複的。
- ID 的值只能是數值。
- ID 必須 64 位元(bits)。
- ID 須依循時間的順序。
- 每秒要能夠生成10000個以上的唯一ID。
第2步:提出高階設計並取得認可
作者介紹了以下四種方式來實作:
- 多master複製(Multi-master replicaiton)
- UUID (通用唯一標識符號)
- 票證伺服器 (Ticket Server)
- Twitter雪片(snowflake)做法
多master複製(Multi-master replicaiton)
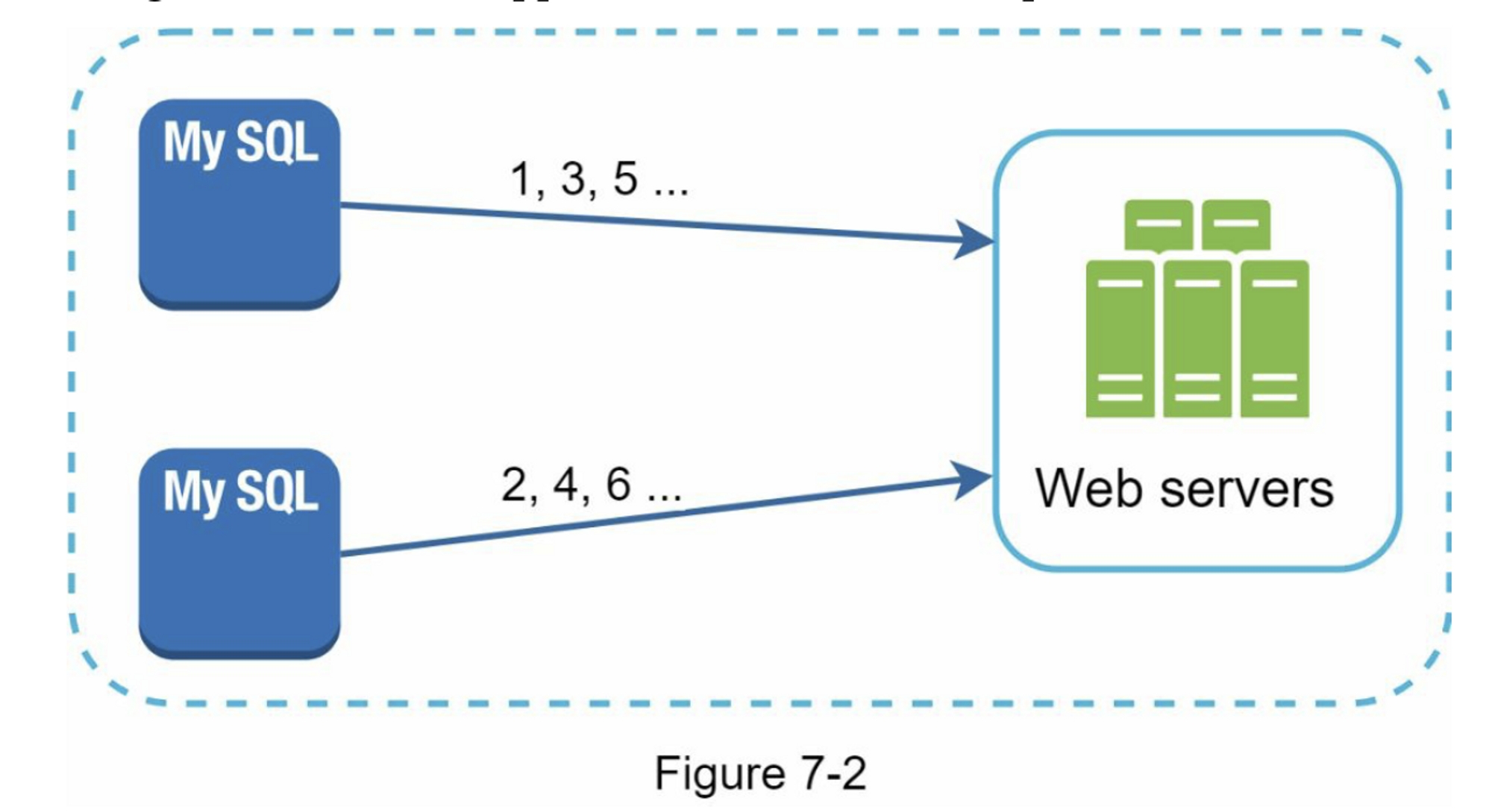
這種做法會用到資料庫的 auto_increment 功能。不過我們並不是把下一個ID增加1,而是增加,其中的就是所使用資料庫伺服器的數量。如圖7-2 所示,只要把同一個伺服器的前一個ID加上2,就可以生成下一個ID。這種做法解決了一些可擴展性的問題,因為 ID 可根據資料庫伺服器的數量進行擴展。
不過,這個策略有一些主要的缺點:
- 如果是採用多個資料中心,這種做法就難以進行擴展。📌每個資料庫都要調整
auto_increment值。 - 由多部伺服器分別得出的ID,其值並不一定隨著時間而增加。
- 添加或移除伺服器時,擴展性並不好。
auto_increment 如下:
-- 設定全域步進值 (影響所有表)
SET @@auto_increment_increment = 2;
-- 或者只影響當前 session
SET SESSION auto_increment_increment = 2;
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50)
);
SET SESSION auto_increment_increment = 3; -- 每次 +3
INSERT INTO users (name) VALUES ('Alice');
INSERT INTO users (name) VALUES ('Bob');
INSERT INTO users (name) VALUES ('Charlie');
-- 結果:
-- id | name
-- 1 | Alice
-- 4 | Bob
-- 7 | Charlie
UUID (通用唯一標識符號)
UUID 是取得唯一ID 的另一種簡便方法。UUID是一個128位元的數字,可用來標識電腦系統中的資訊。UUID 出現重複值的機率非常低。以下內容引自維基百科,「如果每秒產生10億個UUID,大概需要經過100年之後,出現一次重複值的機率才會來到50%」。
這裡就有一個 UUID 的範例: 09c93c62-5064-468d-bf8a-c07e1040bfb2UUID 可獨立生成,而不需要在伺服器之間進行協調。圖7-3呈現的就是UUID 的設計。
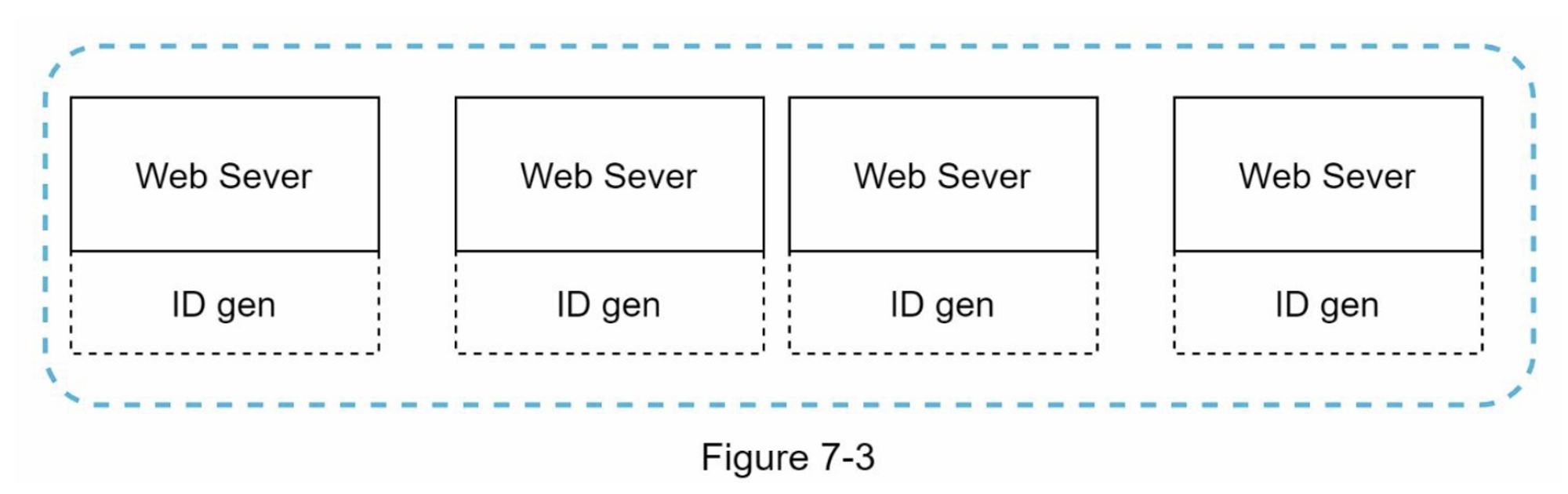
在這樣的設計下,每個 Web 伺服器都有一個ID生成器,而且每個 Web 伺服器都可以各自獨立生成ID。
優點:
- UUID 的生成很簡單。伺服器之間完全不需要進行協調,因此不會出現任何同步問題。
- 這個系統很容易進行擴展,因為每個 Web 伺服器都可以自行生成所
- 要使用的ID。ID 生成器可隨著 Web 伺服器輕鬆進行擴展。
缺點:
- ID 的長度為128位元,但我們的要求是64位元。
- ID 的值並不會隨著時間遞增。
- ID 有可能出現非數字的情況。
票證伺服器 (Ticket Server)
票證伺服器(ticket server)是另一種生成唯一ID 的有趣方式。票證伺服器是由 Flicker 所開發,可用來生成分散式的主鍵(primary key)。這個系統的運作方式很值得特別瞭解一下。
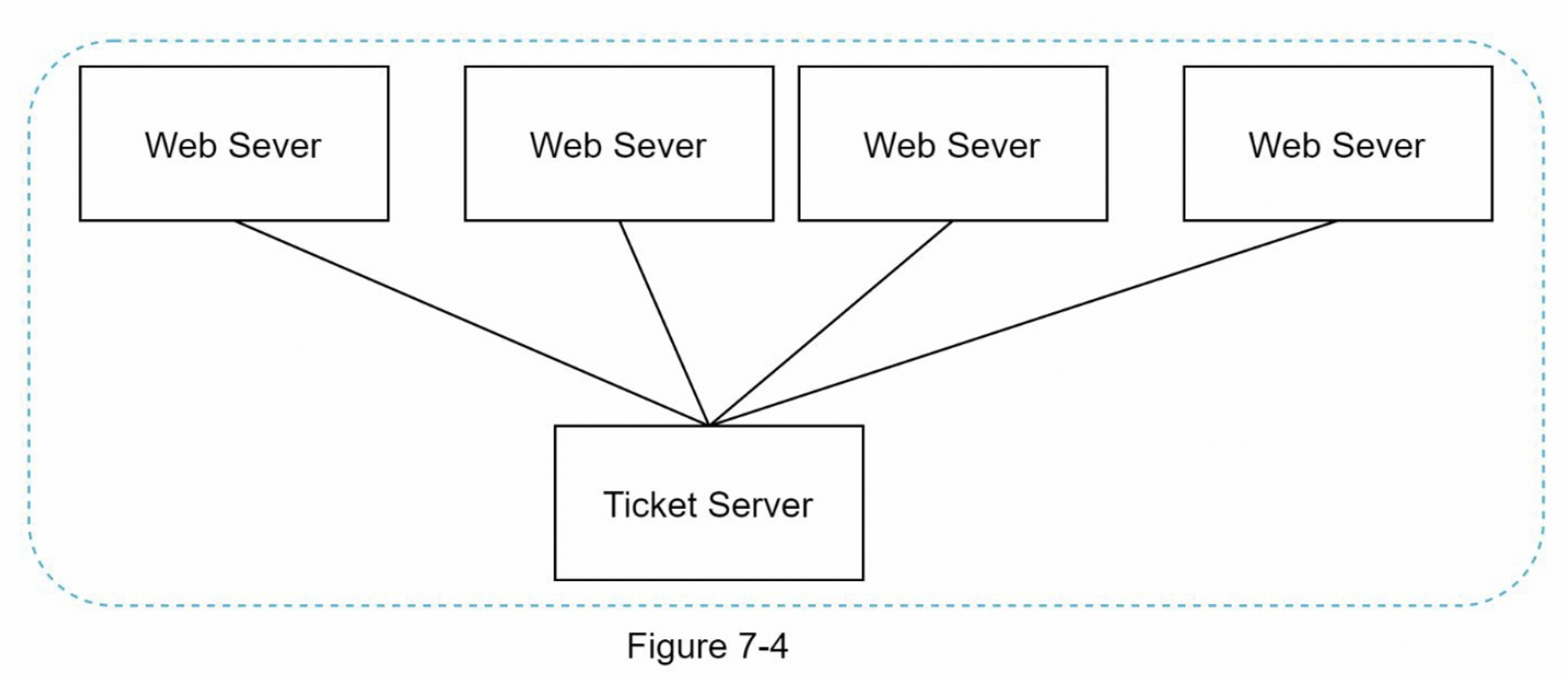
其構想就是在單一資料庫伺服器(票證伺服器)中,使用中央管理式(centralized)的 auto_increment 功能。如果想要瞭解更多相 參考 Flicker 的工程部落格文章 2。
優點:
- 數字 ID。
- 很容易進行實作,而且可適用於中小型應用。
缺點:
- 可能會有單點故障的問題。由於採用單一的票證伺服器,因此票證伺服器若出現故障,所有依賴它的系統全都會遇到問題。為了避免單點故障,我們可以設定多部票證伺服器。不過,這也會帶來新的挑戰,例如資料同步的問題。
Flickr: Ticket Servers — Distributed Unique Primary Keys on the Cheap
文章背景與目的
- 分片(Sharding)與主-主架構
Flickr 將資料分片儲存在多臺 MySQL 上,同時每個分片又採用主—主(master‑master)複製,以提升可靠性與擴充能力。這種架構下,必須確保所有分片生成的 ID 全域唯一,以避免主鍵衝突。 - MySQL
AUTO_INCREMENT無法跨節點保證唯一性
雖然單個 MySQL 實例可以便利地使用AUTO_INCREMENT,但這在多實例間並無全域唯一保障。
為何不使用 GUID(UUID)?
- GUID 體積大、索引效能差
GUID 雖然可保證唯一,但其字串長度及非順序性,會使索引龐大且難以維持在記憶體,導致查詢性能下降。 - 缺乏順序性
Flickr 需要 ID 有一定順序性,有助於報表、debug,以及部分快取策略,GUID 雖唯一但不適合此處需求。
中央 Ticket Server:解決方案核心
- 使用中央 DB 生成 ID
Flickr 使用專門的「Ticket Server」,是一臺專用的 MySQL伺服器,只儲存簡化的 ID 表(如Tickets64)。透過插入一條固定的 stub(stub 欄位)再取得LAST_INSERT_ID(),以產生全域唯一、連續的 ID。 REPLACE INTO機制
他們使用 MySQL 的非標準語法REPLACE INTO(如果 stub 已存在,則先刪除再插入),來確保每次插入都會自動產生新的AUTO_INCREMENTID。
高可用設計:雙 Ticket Server(避免單點故障)
- 雙機部署 + 分隔 ID 空間
為了避免 Ticket Server 成為單點故障(SPOF),架設兩臺伺服器,並採用auto_increment_increment = 2搭配不同的auto_increment_offset(分別為 1 與 2),使一台產生奇數 ID,另一台產生偶數 ID,再以 round-robin 分配請求。
其它實務設計細節
- 多種類別 ID (Sequences)
Flickr 不只一張Tickets64表,還為各種實體(如 Photos、Accounts、OfflineTasks、Groups)設計獨立序列,以避免彼此干擾與快速消耗。 - 簡單但有效的設計哲學
整體方案雖不優雅,但符合 Flickr 所講求的:「工程上最蠢但能運作」原則,且自 2006 年就投入生產並穩定運作。
Twitter雪片(snowflake)做法
前面所提到的一些做法,分別針對不同的ID 生成系統運作原理,提供了一些不同的構想。不過,這些做法全都不符合我們的特定要求,因此我們還需要另一種做法。Twitter 的唯一 ID 生成系統叫做「snowflake (雪片)」,其構想相當具有啟發性,而且可以滿足我們的要求。
分而治之(divide and conquer)的分治做法,可說是我們的好朋友。我們會把ID 分成不同的好幾段,而不是直接生成整個ID。圖7-5顯示的就是64位元 ID的佈局方式。

每一段的說明如下。
- 符號位元 : 1位元。永遠為0。保留以供未來使用。它也許可用來區分有正負號與無正負號的數字。
- 時間戳 : 41 位元。從某個時間點(可自定義)以來所經過的毫秒數。我們使用 Twitter 雪片的預設時間點1288834974657,這個時間就相當於 UTC 2010年11月4日01:42:54。
- 資料中心 ID : 5位元,這裡可以讓我們用來區分2^ 5 = 32 個資料中心。
- 機器 ID : 5位元,每個資料中心可以有2 ^ 5 = 32 部機器。
- 序列編號 : 12 位元。同一部機器/ process 行程所生成的每個ID,其序列編號每次都會以加1的方式逐漸遞增。這個數字每毫秒都會重設為0。
第3步:深入設計
在高階設計中,我們已針對分散式系統討論過一些可用來設計唯一 ID 生成器的各種選項。在這裡我們會選擇 Twitter 雪片 ID 生成器做為參考的做法。接著我們就來深入研究相應的設計。為了重新喚醒我們的記憶,下面重新列出相應的設計圖。

資料中心 ID 與機器 ID 在啟動時就已經選定,通常在系統啟動之後就固定不再改變了。資料中心 ID 與機器 ID的任何修改,都需要進行仔細的檢查,因為如果意外修改了這些值,就有可能導致ID 衝突的情況。ID 生成器在執行時,會生成相應的時間戳與序列編號。
時間戳
最重要的41位元,就是由時間戳所構成。時間戳會隨著時間而遞增,因此ID 也會隨著時間而遞增。圖7-7 顯示的就是如何把二進位表達方式轉換為 UTC的範例。你也可以用類似的方法,把UTC 轉換回二進位表達方式。
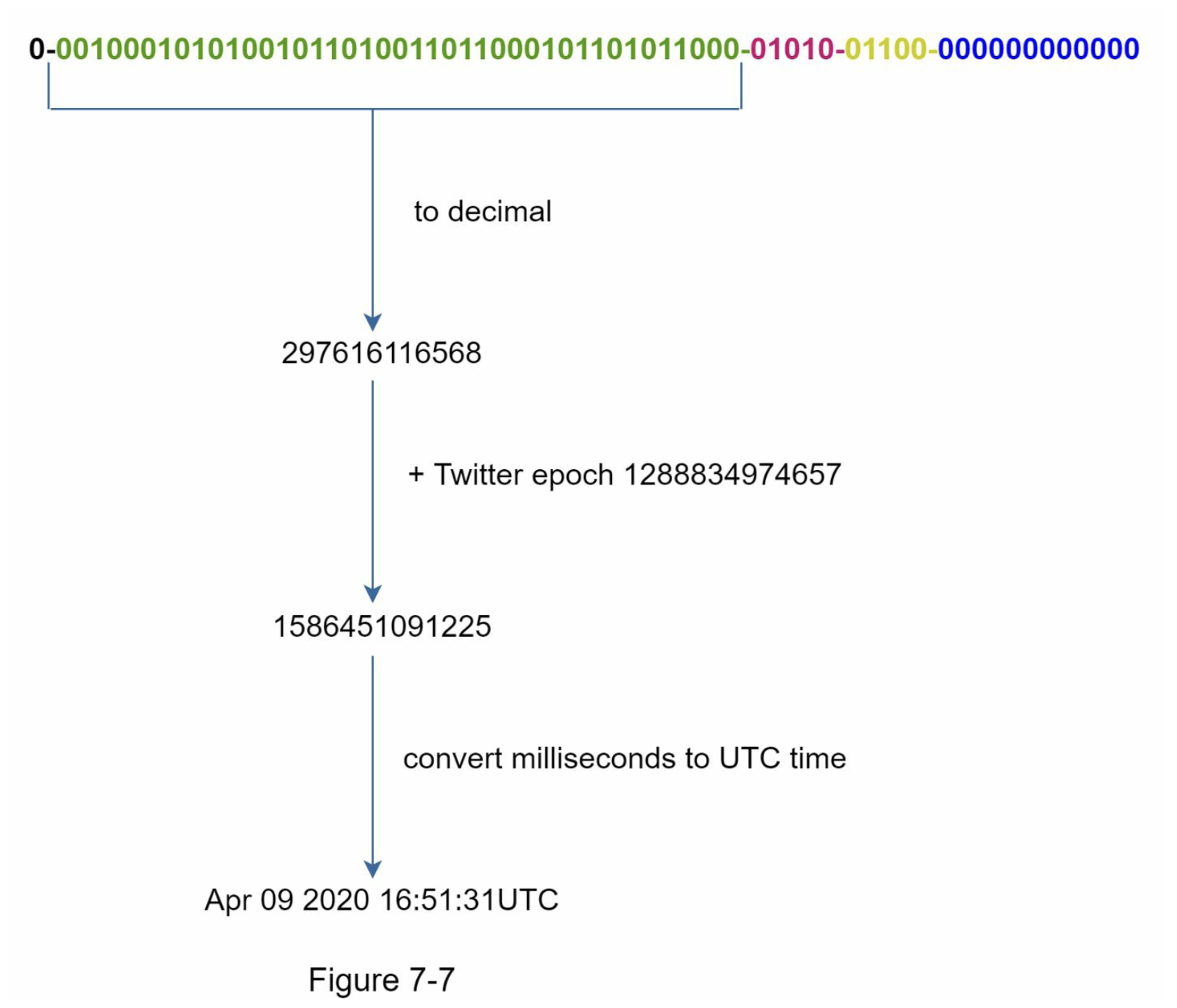
41 位元可以表達的最大時間戳為2 ^41-1 = 2199023255551 毫秒(ms),相當於:~ 69年 = 2199023255551 毫秒 / 1000 秒 / 365天 / 24小時/3600 秒。這也就表示,這個ID 生成器可正常運作69年,如果改用自定義的方式,把起算時間(epoch time)設定成更接近今天的日期,還可以進一步延後這個可正常運作的時間。69年之後,我們就會需要另一個新的起算時間,或是改用其他技術來對這個ID 進行遷移轉換。
序列編號
序列編號有12位元,這給了我們2 ^ 12 = 4096種組合。除非同一部伺服器在一毫秒之內生成了多個ID,否則這個欄位的值就會是0。理論上來說,同一部機器在每毫秒內最多可生成4096個新的ID,即 sequence (每毫秒最多 4096 筆)。
第4步:匯整總結
我們在本章討論了好幾種設計唯一 ID生成器的不同做法:多 master 複製、UUID、票證伺服器,以及 Twitter 的雪片做法。我們最後選擇採用雪片的做法,因為它可支援我們所有的使用需求,而且可以在分散式環境下進行擴展。
如果在面試結束之前還有多餘的時間,這裡還有一些可以額外聊聊的想法:
- 時鐘同步 : 在我們的設計中,我們假設每一部ID 生成伺服器全都具有相同的時鐘。如果伺服器是在多個核心中執行,這個假設就有可能是不正確的。在使用多部機器的做法中,也存在相同的挑戰。時鐘同步解決方案並不在本書的討論範圍之內。不過,瞭解這個 問題的存在是很重要的。採用網路時間協定(NTP;Network TimeProtocol),就是解決此問題最受歡迎的一種做法。
- 各段長度的調整 : 舉例來說,改用比較短的序列編號、但採用比較多的時間戳位元,對於低並行性、跨越時間更長的應用而言,是一種有效而可行的做法。
- 高可用性 : 對於其他任務來說,ID 生成器是非常重要的系統,因此它必須具有很高的可用性。